12款开源数据资产(元数据)管理平台选型分析(一)

两年前,在文章最全大数据开源组件思维导图中,整理了大数据生态的开源技术组件思维导图,至今有4K的下载量。
尽管数据行业的新词热度,由大数据平台->数据治理->数据中台->数字化转型(现代数据技术栈)转换,做为这些新词的基础组成部分,数据资产管理平台/元数据管理平台/数据目录管理平台等技术方案,依旧处于Gartner曲线的爬升恢复期,相关平台百花齐放,一统江湖的开源平台或者商用产品还没出现,在推进企业数字化转型落地过程中,实现数据治理、数据资产管理平台/元数据管理平台/数据目录管理平台的选型,依旧是一项考验人能力的活。
计划分三篇文章详细介绍12款优秀的开源数据资产/元数据管理平台,在第三篇文章中,将通过一张选型二维表,全面对比12款开源软件的功能特性。
本文整理了其中Apache atlas、Datahub、Marquez、Amundsen四款产品,并简单分析其优缺点,供选项参考:
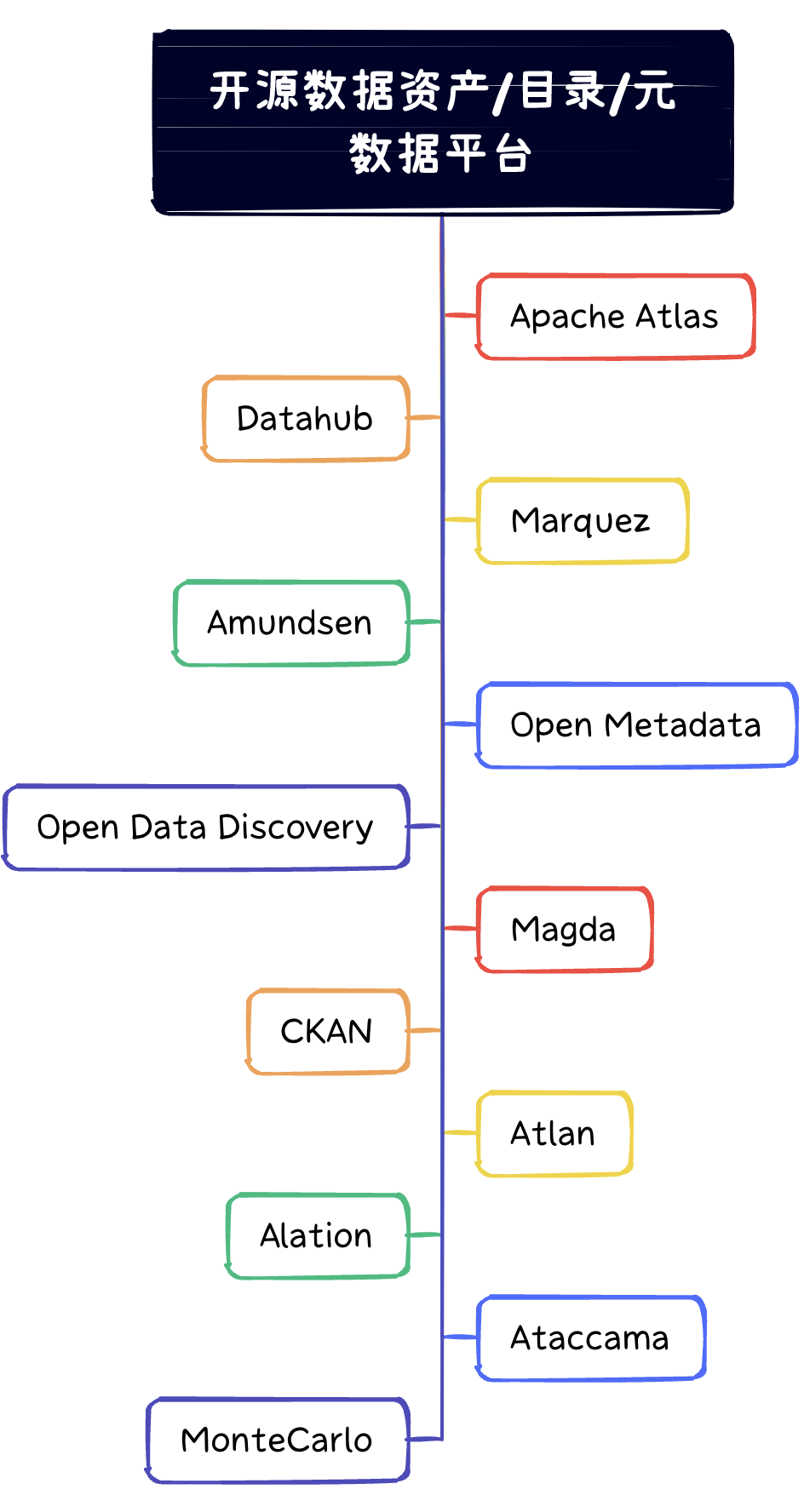
Apache Atlas
开源地址:https://github.com/apache/atlas 1.5K star
Atlas最早由大数据平台三驾马车(Cloudera,Hortonworks,MapR)之一HortonWorks公司开发,用来管理Hadoop项目里面的元数据,进而设计为数据治理的框架,它为Hadoop集群提供了包括数据分类、集中策略引擎、数据血缘、安全和生命周期管理在内的元数据治理核心能力。后来开源出来给Apache社区进行孵化,得到Aetna,Merck,Target,SAS,IBM等公司的支持进行发展演进。因其支持横向海量扩展、良好的集成能力和开源的特点,国内大部分厂家选择使用Atlas或对其进行二次开发。
目前,Cloudera,Hortonworks已经并购,MapR也鲜有新品。大数据技术领域,相较于Hadoop技术平台风头正盛的2016年,已经发生了巨大的变化,Hadoop体系正在逐步淡出舞台中央。MPP、现代技术栈、云原生数据库等登上舞台,例如Clickhouse、Doris、StarRocks、Databend、Materialize、Ringswave。
Atlas的优点:
- 大厂开源,深度集成Hadoop生态中的Hive,支持表级、字段级血缘
- 与HDP原生集成,支持对接Ranger实现行列级数据权限管控,安装便捷省心
- 强大的元数据元模型,支持元数据定制及扩展
- 源代码不复杂,国内有大量平台基于Atlas定制修改为商用产品
Atlas的不足:
- 其优势也是劣势,母开源公司已被并购,历史悠久,不再是一种优势,反而是一种负担
- Hadoop体系已经走向衰退,如何只是完美支持Hive和Hadoop体系,已经无法满足现在快速发展的技术要求
- 其设计界面复杂,体验老旧、数据目录及数据检索都不够便捷
- 使用体验复杂及产品功能更聚焦于解决技术人员的问题,而非数据的最终用户,比如业务人员
- 生态渐渐失去新鲜感、新的类似平台不断发展
相关介绍:https://mp.weixin.qq.com/s/MvaxSF74NE0E43i4rQEb3g
选型建议:1)如果您只有Hadoop生态,可以试试。2)如果您的数据资产是面向数据团队的技术人员,可以试试。
Datahub
开源地址:https://github.com/datahub-project/datahub 7.2K star
DataHub是由Linkedin开源的,官方Slogan:The Metadata Platform for the Modern Data Stack - 为现代数据栈而生的元数据平台。目的就是为了解决多种多样数据生态系统的元数据管理问题,它提供元数据检索、数据发现、数据监测和数据监管能力,帮助大家解决数据管理的复杂性。
DataHub基于Apache License 2开源,采用基于推送的数据收集架构(当然也支持pull拉取的方式),能够持续收集变化的元数据。当前版本已经集成了大部分流行数据生态系统接入能力,包括但不限于:Kafka, Airflow, MySQL, SQL Server, Postgres, LDAP, Snowflake, Hive, BigQuery。
Datahub的优点:
- 名门开源,与Kafka同家庭。社区活跃,发展势头迅猛,版本更新迭代迅速。
- 定位清晰且宏远,Slogan可以看出团队的雄心壮志及后期投入,且不断迭代更新的版本也应证了这一点。
- 底层架构灵活先进,未扩展集成而生,支持推送和拉去模式,详见:https://datahubproject.io/docs/architecture/architecture/
- UI界面简单易用,技术人员及业务人员友好
- 接口丰富,功能全面
Datahub的不足:
- 前端界面不支持国际化,界面的构建和使用逻辑不够中国化
- 版更更新迭代快,使用后升级是个难题
- 较多功能在建设中,例如Hive列级血缘
- 部分功能性能还需要优化,例如SQL Profile
- 中文资料不多,中文交流社群也不多
相关介绍:
https://mp.weixin.qq.com/s/74gK3hTt7-j1lTbKFagbTQ
https://mp.weixin.qq.com/s/iP6sc2DzPaeAKpSWNmf8hQ
选型建议:
1)如果有至少半个前端开发人员+后台开发人员;
2)如果需要用户体验较好的数据资产管理平台;
3)如果有需要扩展支持各种平台、系统的元数据。请把Datahub列为最高选择。
尽管列举了一些不足,但是开源产品中Datahub目前是相对最好的选择。笔者也在生产中使用,有问题的可以随时沟通交流。
商用版本: Metaphor(https://metaphor.io/)是Datahub的SaaS版本。
Marquez
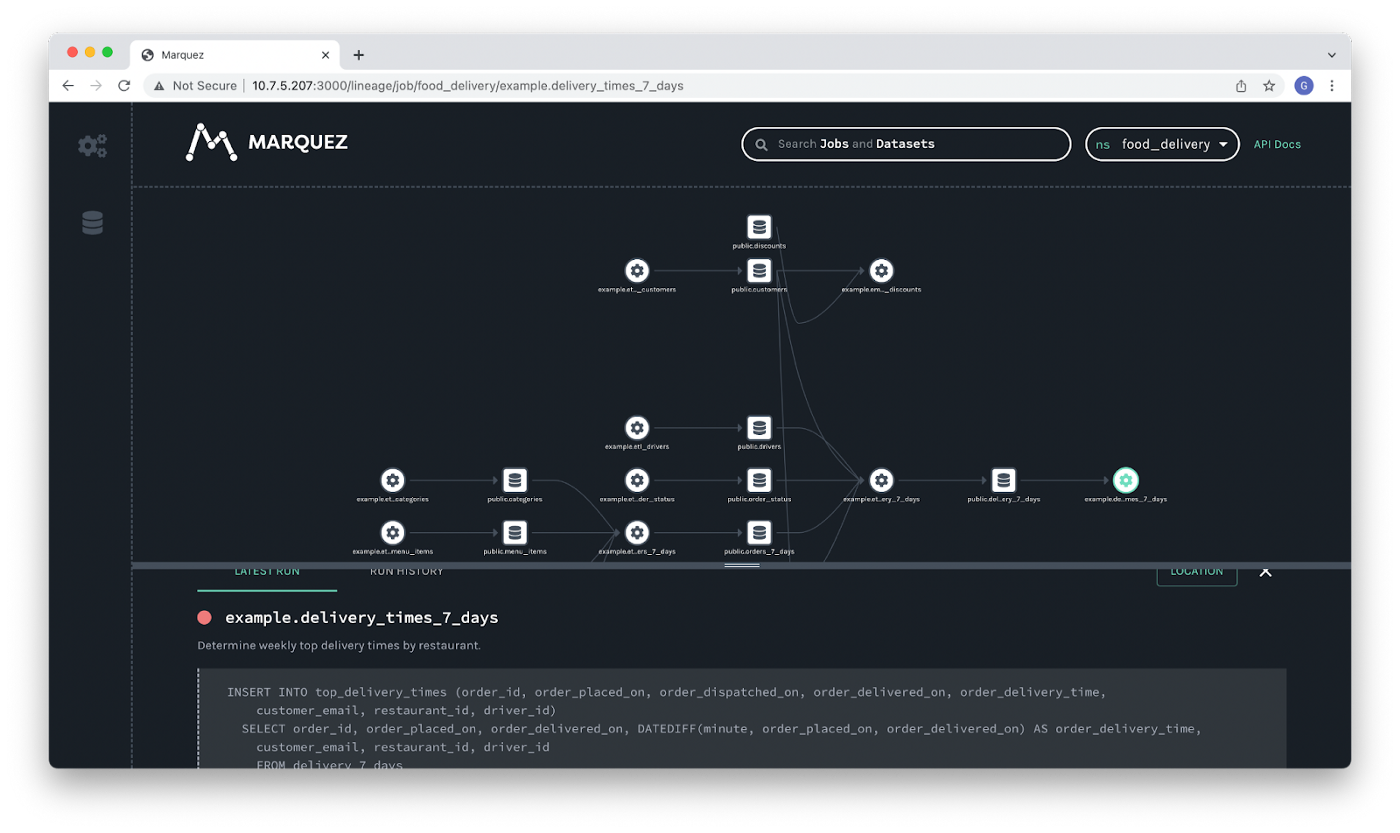
开源地址:https://github.com/MarquezProject/marquez 1.3K star
Marquez的优点:
- 界面美观,操作细节设计比较棒
- 部署简单,代码简洁
- 依靠底层OpenLineage协议,结构较好
Marquez的不足:
- 聚焦数据资产/血缘的可视化,数据资产管理的一些功能,需要较多开发工作
相关介绍:https://mp.weixin.qq.com/s/OMm6QEk9-1bFdYKuimdxCw
选型建议:
1)如果您有功能强大的元数据及数据资产管理平台后端,仅需要数据资产的可视化及血缘展示,可以考虑使用体验。
2)界面展示比较棒,支持选择依赖线路高亮及隐藏支线依赖。要做到数据资产管理、元数据采集有较多的工作要做。
商用版本:
Datakin(https://datakin.com/) 是Marquez的SaaS版本. 支持 Apache Hive, Amazon RDS, Teradata, Amazon Redshift, Amazon S3, and Cassandra.
Amundsen
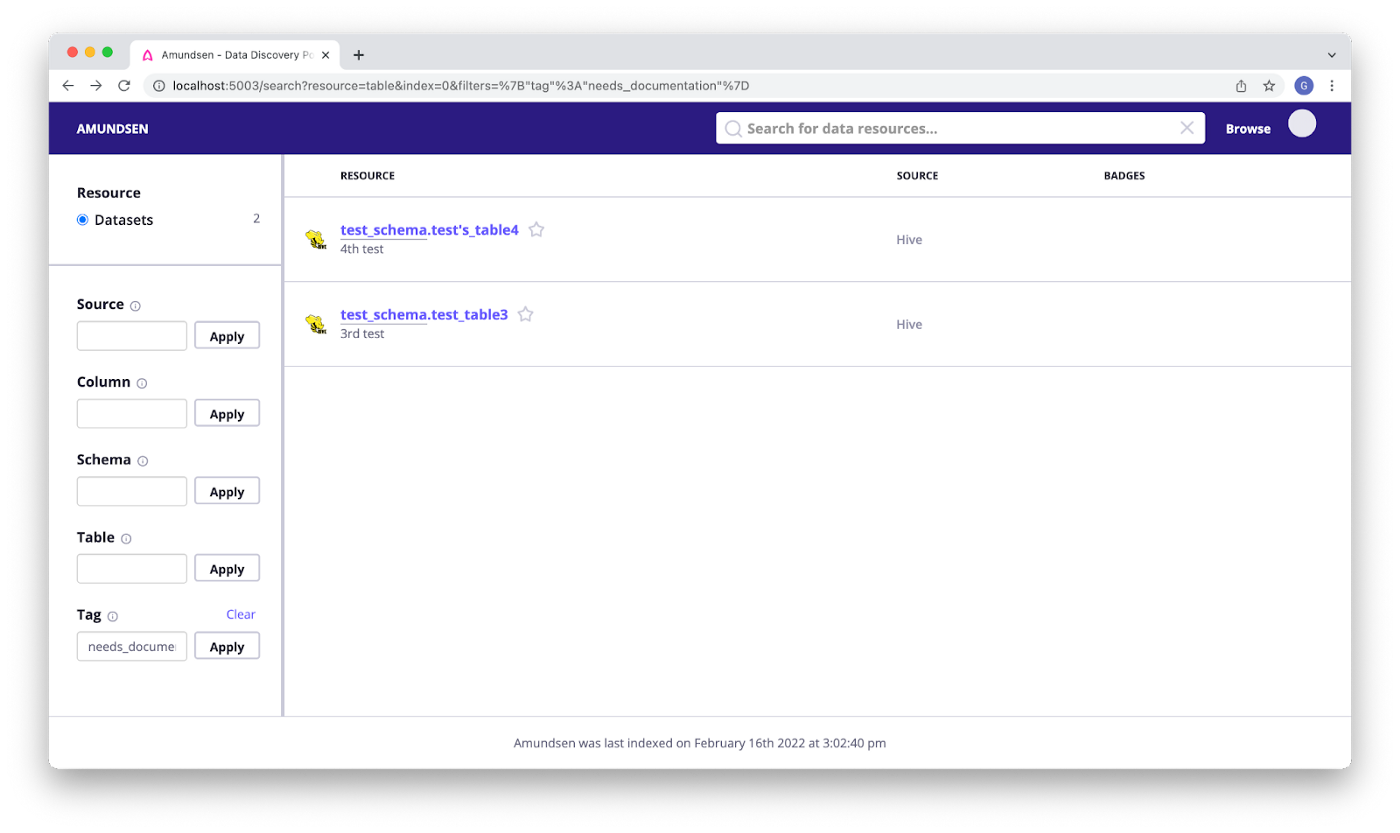
开源地址:https://github.com/amundsen-io/amundsen 3.8K star
Amundsen 是来自Lyft 开源的元数据管理、数据发现平台,功能点很全,有一个比较全的前端、后端以及数据处理框架
Amundsen的优点:
- Lyft大厂开源,社区活跃,版本更新较多
- 定位清晰明确,与Datahub类似,致力于成为现代数据栈中的数据目录产品
- 支持对接较多的数据平台与工具
Amundsen的不足:
- 中规中矩的UI界面,操作便捷性不足
- 中文文档不多
- 血缘、标签、术语等功能方面不如Datahub使用便捷
- 较多支持友好的组件,国内使用的不多
相关介绍:
https://mp.weixin.qq.com/s/yGZ1RJs2seu943sswxYYzw
https://mp.weixin.qq.com/s/5w6euvUWzm5RWXgisB-rMg
https://mp.weixin.qq.com/s/iVocnMV8zuQN-jcID83nSg
选型建议:
1)如果有人折腾,建议选择Datahub,如果没人折腾,选择Amundsen够折腾
商用版本: Stemma(https://www.stemma.ai/)是Amundsen的SaaS 版本。
总结
数据治理、数据资产管理等工作,是企业数字化转型中的底层基建,很重要,却又很难体现出效果和价值。上层数据战略、数据架构、数据流程、数据规范等问题,在组织层面没有解决;不论数据资产平台等工作规划和实现得如何好,都只能体现出杯水车薪的效果。