gplearn原理解析及参数分析
gplearn简介
基于sklearn的遗传算法框架、
gplearn 基本原理
函数和变量的二叉树组合得到一个复杂的公式

初始化思路
初始化 population_size 棵树, 每棵树随机生成,受到二元组 init_depth 限制( min_depth ,
max_depth ),
初始化方法由 init_method 参数管理,分为三种子策略
grow
生成树的思路,公式从根节点开始生长,随机选择函数和变量,遇到变量停止,成为一个叶子节点。 由于函数和变量的选择概率一致,在变量大于函数的时候,树的深度较浅。
full
完全二叉树思路,除最后一层外,其余节点均为函数。
half grow and half full
各一半
优化目标
SymbolicRegressor
- mae: mean absolute error
- mse: mean squared error
- rmse: root mean squared error
SymbolicTransforme
新特征与目标变量之间的相关系数的绝对值
公式的进化reproduction
交叉crossover
优胜者内随机选择一个子树,替换为另一棵公式树的随机子树。此处的另一棵公式树通常是剩余公式树中适应度最高的。

子树变异 Subtree Mutation
优胜者的一棵子树将被另一棵完全随机的全新子树代替。
p_subtree_mutation控制

hoist变异 Hoist Mutation
从优胜者公式树内随机选择一个子树A,再从A里随机选择一个子树B,然后把B提升到A原来的位置,用
B替代A。

点变异 Point Mutation
由 p_point_replace 参数控制。一个随机的节点将会被改变
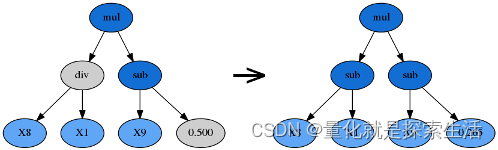
对抗公式膨胀(类似于对抗过拟合)
节俭系数
parsimony_coefficient 惩罚过于复杂的公式
hoist 变异
仅选取部分样本
gplearn 源码
SymbolicRegressor
-
population_size: 整数,可选(默认值=1000)种群规模(每一代个体数目即初始树的个数)。 -
generations: 整数,可选(默认值=20)要进化的代数。 -
tournament_size: 整数,可选(默认值=20)进化到下一代的个体数目(从每一代的所有公式中,tournament_size个公式会被随机选中,其中适应度最高的公式将被认定为生存竞争的胜利者,进入下一代。决定算法收敛速度。 -
stopping_criteria: 浮点数,可选(默认值=0.0)停止条件。 -
const_range: 两个浮点数组成的元组,或none,可选(默认值=(-1,1))公式中所要包含的常量取值范围。如果设为none,则无常数。 -
init_depth: 两个整数组成的元组,可选(默认值=(2,6))用来表示原始公式初始总体的树深度范围,树的初始深度将处在(min_depth,max_depth)的区间内(包含端点)。原始公式初始总体的树深度范围,单个树将随机选择此范围内的最大深度。 -
init_method: 字符串, 可选(默认值=‘half and half’)控制每棵公式树的初始化方式,有三种策略, ‘full’ 和 ‘grow’: -
function_set: 字符串, 用于符号回归的函数,包括gplearn原始提供以及自定义 -
- ‘add’ : addition, arity=2.
-
- ‘sub’ : subtraction, arity=2.
-
- ‘mul’ : multiplication, arity=2.
-
- ‘div’ : protected division where a denominator near-zero returns 1., arity=2.
-
- ‘sqrt’ : protected square root where the absolute value of the argument is used, arity=1.
-
- ‘log’ : protected log where the absolute value of the argument is used and a near-zero argument returns 0., arity=1.
-
- ‘abs’ : absolute value, arity=1.
-
- ‘neg’ : negative, arity=1.
-
- ‘inv’ : protected inverse where a near-zero argument returns 0., arity=1.
-
- ‘max’ : maximum, arity=2.
-
- ‘min’ : minimum, arity=2.
-
- ‘sin’ : sine (radians), arity=1.
-
- ‘cos’ : cosine (radians), arity=1.
-
- ‘tan’ : tangent (radians), arity=1.
-
metric: 字符串, 目标函数(损失函数) (默认值=‘MAE’(平均绝对误差)),此外还包括gplearn提供的mse等,也可以自定义。 -
parsimony_coefficient: 浮点数或 “auto”, 可选 (默认值=0.001)用于惩罚过于复杂的公式。简约系数往往由实践验证决定。如果过于吝啬(简约系数太大),那么所有的公式树都会缩小到只剩一个变量或常数;如果过于慷慨(简约系数太小),公式树将严重膨胀。不过,gplearn已经提供了’auto’的选项,能自动控制节俭项的大小。 -
p_crossover: 浮点数, 可选 (默认值=0.9)对胜者进行交叉的概率,用于合成新的树 -
p_subtree_mutation: 浮点数, 可选 (默认值=0.01)控制胜者中进行子树变异的比例(优胜者的一棵子树将被另一棵完全随机的全新子树代替)所选值表示进行子树突变的部分。 -
p_hoist_mutation: 浮点数, 可选 (默认值=0.01) 控制进行hoist变异的比例,hoist变异是一种对抗公式树膨胀(bloating,即过于复杂)的方法:从优胜者公式树内随机选择一个子树A,再从A里随机选择一个子树B,然后把B提升到A原来的位置,用B替代A。hoist的含义即「升高、提起」。 -
p_point_mutation: 浮点数, 可选 (默认值=0.01)控制点进行突变的比例 -
p_point_replace: 浮点数, 可选 (默认值=0.05)对于点突变时控制某些点突变的概率。 -
max_samples: 浮点数, 可选 (默认值=1.0)从样本中抽取的用于评估每个树(成员)的百分比 -
feature_names: list(列表), 可选 (默认值=None)因子名(或特征名)若为none则用x0,x1等表示。 -
warm_start: 布尔型, 可选 (默认值=False)用于选择是否使用之前的解决方案 -
low_memory: 布尔型, 可选 (默认值=False)用于选择是否只保留当前一代 -
n_jobs: 整数,可选(默认值=1)用于设置并行计算的操作 -
verbose: 整数,可选(默认值=0)类似TensorFlow,keras中的verbose -
- verbose = 0日志显示
-
- verbose = 1为输出进度条记录
-
- verbose = 2为每个epoch输出一行记录
-
random_state: 整数, RandomState实例 或者 None, 可选(默认值=None)如果是int,则random_state是随机数生成器使用的种子;如果是random state实例,则random_state是随机数生成器;如果没有,则随机数生成器是使用的RandomState实例按“np.random”。
SymbolicClassifier
新增参数
class_weight: 字典, ‘balanced’ or None(default)-
- None : 所有类型权重为 1
-
- ‘balanced’:对y输入权重平衡, n_samples/(n_classes*np.bincount(y))
SymbolicTransformer
新增参数
hall_of_fame: 整数,可选(默认值=100), 从最终进化一代选择hall_of_fame个数, 用于比较n_components:整数,可选(默认值=10), 从hall_of_fame中输出最优的n_components个结果
参考
gplearn中SymbolicRegressor的参数介绍
【Python机器学习】用遗传算法实现符号回归——浅析gplearn