Neuroscout:可推广和重复利用的fMRI研究统一平台
摘要
功能磁共振成像 (fMRI) 已经彻底改变了认知神经科学,但方法上的障碍限制了研究 结果的普遍性。Neuroscout,一个端到端分析自然功能磁共振成像数据 的平台, 旨在促进稳健和普遍化的研究推广。Neuroscout利用最先进的机器学习模型来自动注释来自使用自然刺激的数十个功能磁共振成像研究中的刺激—— 比如电影和叙事——使研究人员能够轻松地跨多个生态有效的数据集测试神经科学假设。此外,Neuroscout建立在开放工具和标准的强大生态系统上,提供易于使用的分析构建器和全自动执行引擎, 以减少可重复研究的负担。通过一系列的元分析案例研究,验证了自动特征提取方法,并证明了其有支持更稳健的功能磁共振成像研究的潜力。由于其易于使用和高度自动化,Neuroscout克服了自然分析中常见出现的建模问题,并易于在数据集内和跨数据集进行规模分析,可以自利用一般的功能磁共振成像研究。
1.前言
当前功能磁共振成像研究的一个关键弱点在于其概括性—即,从个别研究得出的结论是否适用于不受参与者样本和实验条件影响的研究。一个主要的问题是在大多数功能磁共振成像研究中使用的刺激的类型不同,而且实验条件下的刺激在复杂性和认知需求上与现实世界环境根本不同,这让人质疑产生的推论是否在实验室之外适用生态环境。此外,主要的统计分析方法通常不能模拟与刺激相关的变异性。因此,许多研究——尤其是那些依赖于小刺激集的研究——可能高估了其统计证据的强度, 以及它们对新的但同等刺激的普遍性。又由于数据收集的成本,功能磁共振成像研究往往动力不足,结果可能无法在新的参与者样本上复制。
使用类似生命刺激的自然主义范式已被提倡作为提高功能磁共振成像研究的普遍性的一种方式,比如电 影和叙事等刺激具有丰富、多维的变化,为在更生态的环境中测试高度控制实验的假设提供了机会。然而,尽管公开可用的自然数据集激增,建模数据变得越困难。因为自然主义特征难以描述 ,并以复杂和意想不到的方式与潜在的混淆同时出现。在精细的时间分辨率下对事件进行注释很费力,这也限制了可以实际定义和建模的变量的数量。因此,在 自然主义数据中隔离刺激的特定特征和大脑活动之间的关系尤其具有挑战性,这阻碍了研究人员进行自然主义实验,并限制了对现有公共数据集的重用。
现在拥有数百个公开可用的神经成像数据集,包括几十个自然主义的功能磁共振成像数据集。标准化的质量控制和预处理管道的开发,如MRIQC ,fmriprep和C-PAC,促进了它们的分析,并可以在新兴的云平台上启动,如https://brainlife.io/about。然而,fMRI模型规范和估计仍然面临困难,通常会导致定制建模管道不能共享,并且难以重用。所以,尽管有一个丰富的工具生态系统,但一个完整的、可重复的工作流程仍然无法实现。
Neuroscout:一个统一的平台,可对自然功能磁共振成像数据进行概括和可重复的分析。Neuroscout在三个关键方面改进了当前的研究实践。首先,Neuroscort为投标数据集提供了一个易于使用的接口,将社区开发的各种资源生态系统无缝集成到一个统一的工作流中。其次,Neuroscout鼓励重新分析公共自然数据集,采用最先进的特征Neuroscout提取算法(如图1)。最后,通过使用标准化模型规范和自动化工作流,Neuroscout使研究人员能够在多个 (和不同的) 数据集上以统一的方式进行假设检验,促进更普遍化的多数据集工作流研究,如元分析。
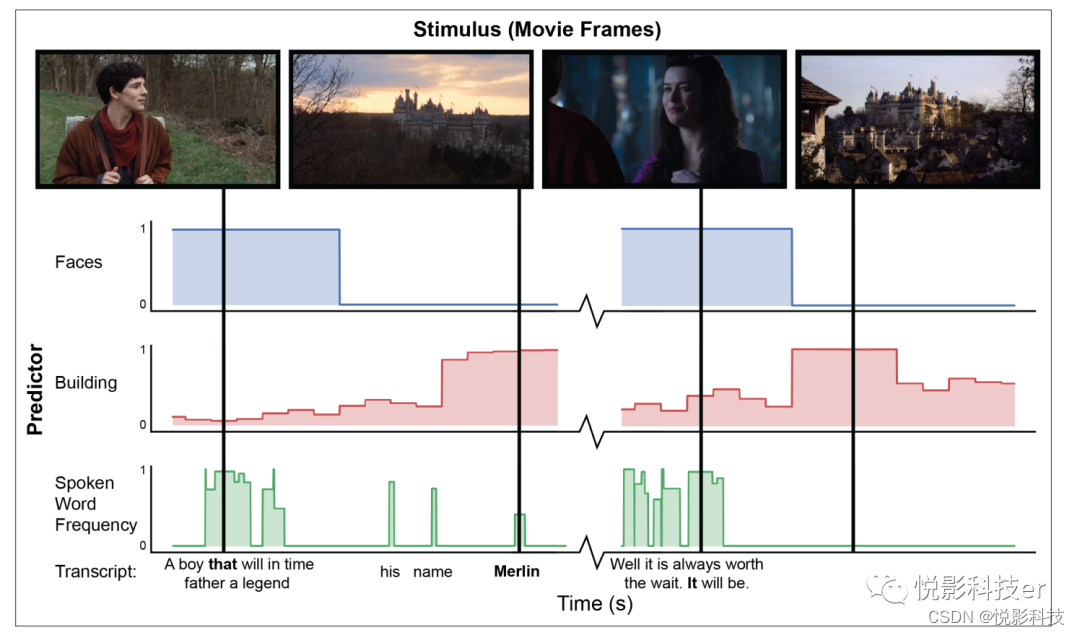
图1.从“Merlin”数据集中对刺激进行自动特征提取的例子。从a处的视频刺激中提取视觉特征,采样频率为1赫兹。“面孔”:应用级联卷积网络( cascaded convolutional network)检测面孔的存在。“建筑”:我们使用Clarifai的通用图像识别模型来计算每一帧中建筑存在的概率。“口语频率”编码表示文本中单词的词汇频率,由SubtlexUS数据库确定。语言特征提取使用语音转录本与通过强制对齐精确的逐字时间确定。
2. 结果
2.1 平台概述
Neuroscout平台由三个主要组件组成:数据获取和特征提取服务器、交互式分析创建工具和自动模型拟合工作流。该平台的所有元素都可以无缝集成,并可以通过交互式方式在线访问 (https://neuroscout.org) 。Neuroscout对一组公开的自然研究功能磁共振成像数据集进行了索引,并从实验刺激中自动提取视觉、 听觉和语言事件的注释。数据集使用robust BIDScompliant pipelines进行协调、预处理和提取。刺激的注释使用pliers自动提取 (McNamara et al.2017) ,这是一个全面的特征提取框架,支持最先进的算法和深度学习模型 (图1) 。目前可用的特性包括数百个预测器编码的两个低级别(e.g.亮度、 响度)和中等水平(e.g.物体识别指标)视听刺激的属性, 以及来自强制对齐的语音文本的自然语言属性。词汇频率注释)。可用的预测器集可以通过社区化以及公开共享的深度学习模型存储库来扩展。随着机器学习模型的不断发展,它将有可能自动从自然刺激中提取更高层次的特征。所有提取的预测器都是通过一种交互式web工具公开共享,目前也正在开发允许通过人工进一步细化提取特征。web应用程序可以方便地创建、完全复制功能磁共振成像分析 (图2a) 。
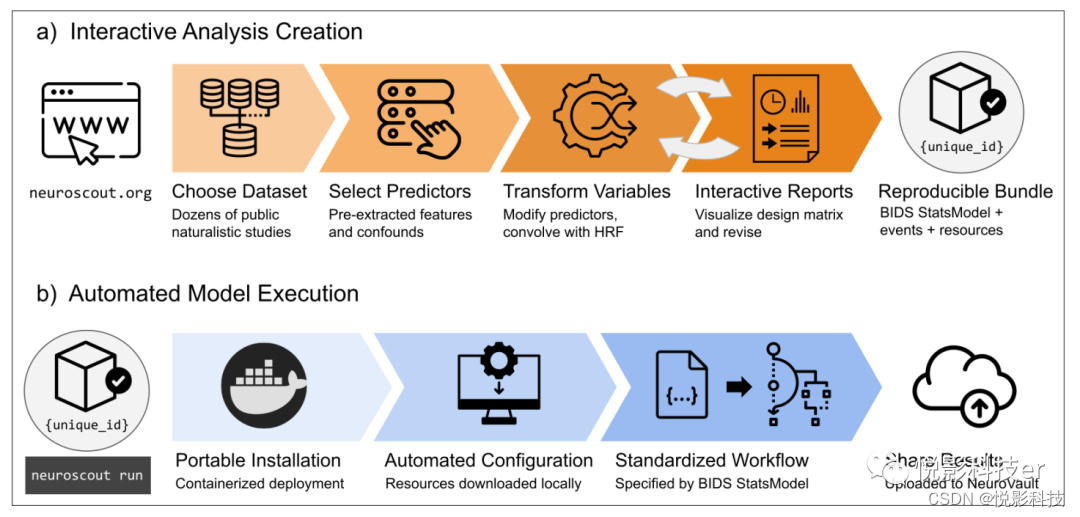
图2. 分析创建和模型执行的概述示意图。(a)交互式分析的创建是通过web应用程序来实现的,产生一个完全指定的可重复的分析包 。(b)自动模型执行是通过容器模型拟合工作流通过零配置实现的,结果会自动在公共存储库NeuroVault中提供。
为了构建分析,用户选择一个数据集和任务进行分析,并在预先提取的数据中进行选择预测器和包括在模型中得混杂因素,并指定统计比较内容。原始预测值可以通过模型变量转换来修改,如缩放、阈值化、正交化和血流动力学卷积。在内部,多级统计模型的所有元素都使用BIDS统计模型规范标准表示,确保了透明度和可再现性。此时,用户可以通过质量控制报告和设计矩阵和预测器协方差矩阵的交互式可视化来检查模型,必要时迭代细化模型。最终完成的分析被锁定,无需进一步修改,分配一个唯一的标识符,并打包到一个包。Neuroscout的自动模型执行工作流程在单个命令行中执行 (图2b) 。完成后阈值统计地图和来源元数据将提交给NeuroVault这个统计地图的公共存储库,确保遵守FAIR (可查找、可访问、互操作和可重用) 科学原则。最后, Neuroscout员自动生成参考文献列表。
2.2 旨于推广化的可伸缩工作流
自动特征提取和标准化的模型规范允许在许多数据集上操作和测试等效假设,跨越更大参与者样本和更多样化的刺激范围。Neuroscout的数据集重视广义推理,分析也集中在三种特征模式 (视觉、听觉和语言) 上,从信号的低水平特征 (响度、亮度、语音的存在和镜头变化),到具有良好的焦点相关性的中层特征(建筑、面孔、工具、景观和文本的视觉存在)。对于每个特征和刺激,拟合了一个全脑单变量GLM,以目标特征作为唯一的预测器,同时考虑协变量(详见方法)。最后使用基于随机效应图像的元分析(IBMA) 结合了20项研究的估计,得到了每个特征的共识统计图。使用简单的单一预测器方法也观察到稳健的元分析激活模式,与现有文献的预期基本一致(图3)。观察到亮度导致初级视觉皮层的激活、建筑和景观导致海马旁位置区(PPA)激活、文本导致视觉文字形成区(VWFA)激活、以及工具图片导致与动作感知和动作记忆相关的外侧枕颞叶皮层(LOTC)和顶叶激活。对于听觉特征,观察到初级听觉皮层对响度的激活,以及颞上沟和回活动对言语的反应。对于短视频(较少研究),产生了在额叶视野、楔前叶和顶叶区域的激活,传统上这些激活涉及注意定向和参考框架的转移。唯一例外是未能检测到梭状体面部区域(FFA)活动对面部的反应(图5),我们将在下面的章节中分析这个结果。
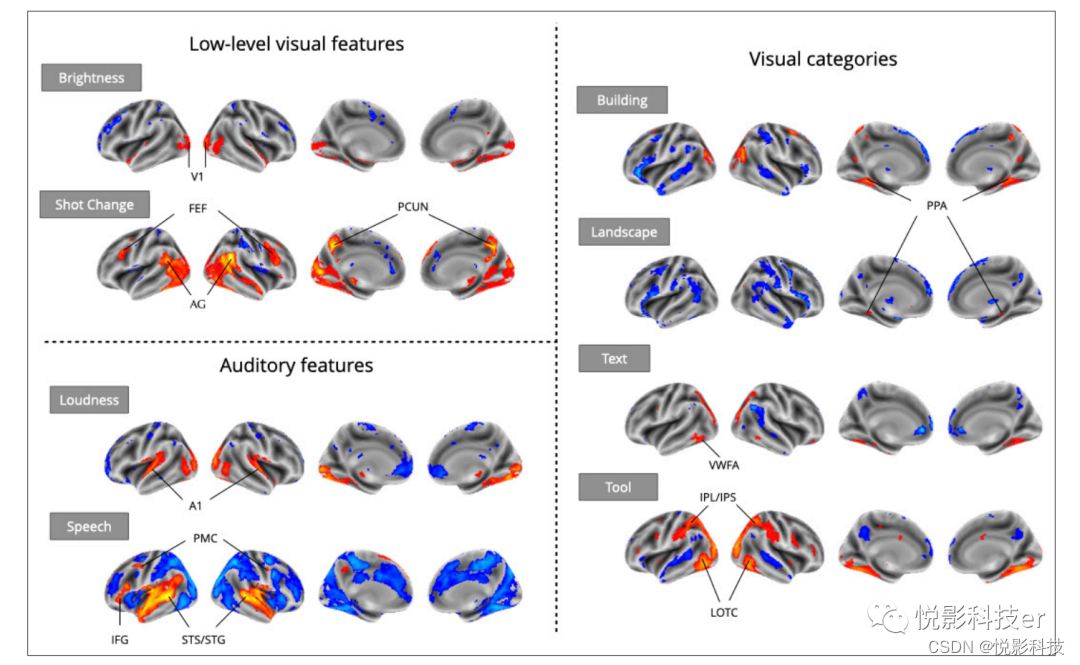
图3.GLM模型的元分析统计图,针对各种效应与fMRI研究的强大先例。单个的GLM模型拟合了每个感兴趣的效应,并使用基于图像的元分析组合了数据集水平的估计。图像的阈值为Z=3.29 (P<0。001)体素。缩写:V1=初级视觉皮层;FEF =额眼视野;AG =角回;PCUN =楔前叶;A1=初级听觉皮层;PMC =运动前皮层;IFG =额下回;STS =颞上沟;STG =颞上回;PPA =海马旁位置区;VWFA =视觉词形区;IPL =下顶叶小叶;IPS =顶叶下沟;LOTC =外侧 枕颞皮层。
尽管研究水平的结果在很大程度上显示出了可信的激活模式,但在不同的数据集中,广泛的特殊变化是明显的。将四个单一研究结果的样本与荟萃分析(N=20)进行比较的三个特征,如图4所示,对于建筑物,几乎在所有研究中都观察到PPA的活动。然而,在前颞叶(ATL)一些研究表明失活,其他激活,而其他研究没有关系。这种不一致在元分析中表明与“建筑物”和ATL没有关系,但证实了与PPA有很强的关联。类似的研究特异性变异可以在其他特征中观察到。这些结果突出了从单一数据集得出推断的局限性,相比之下,多数据集元分析方法在本质上对特定刺激物的变化更稳健,结论可更泛化。
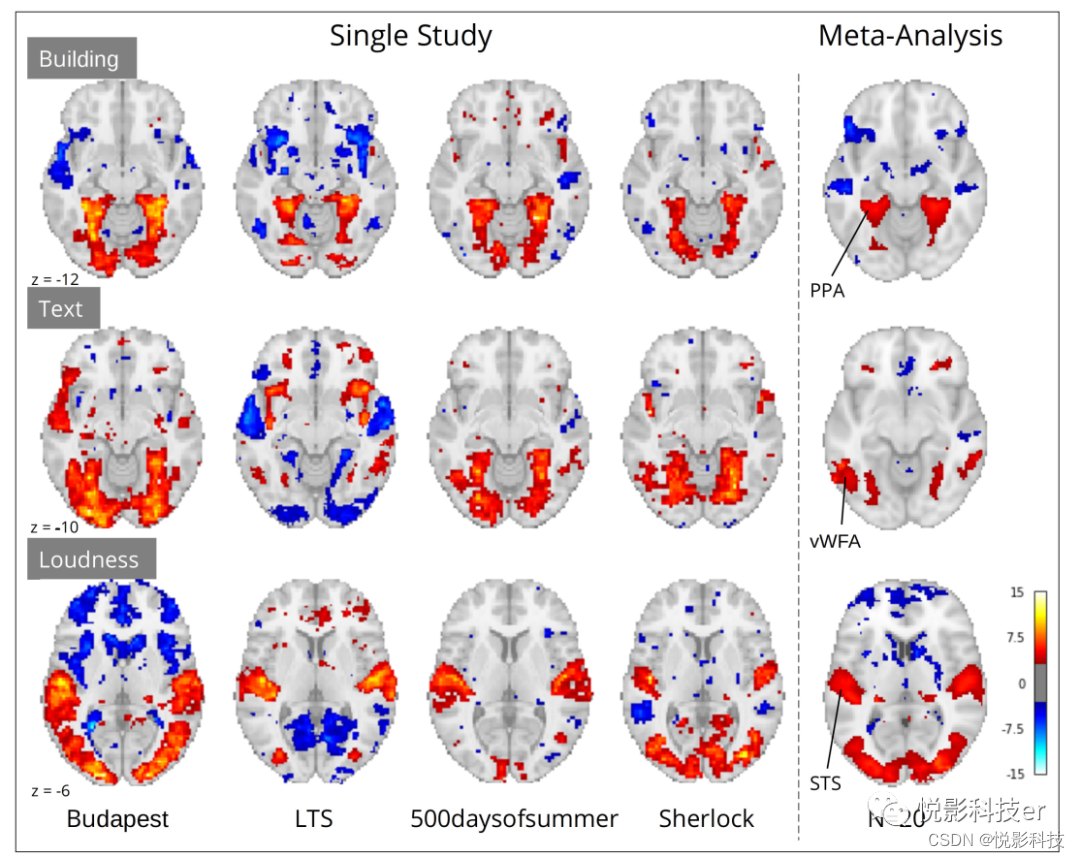
图4.四个单一研究结果的样本与荟萃分析(N=20)进行比较的三个特征
(数据库Budapest, Learning Temporal Structure (LTS), 500daysofsummer task from Naturalistic Neuroimaging Database,和Sherlock)
2.3 灵活化添加自然分析的协变量
单一预测模型未能解释自然刺激中存在的复杂场景动态。与控制实验设计不同, 自然刺激的特征是认知相关事件之间的系统共发生。不解释这种共享方差会混淆模型估计,掩盖归因于兴趣预测因素的真实效应。Neuroscout构建迭代模型,以控制和评估各种潜在混杂因素的影响,而不需要额外的数据收集或人工特征注释,分析报告可视化了设计矩阵的相关结构,提示协变量如何选择和解释。通过迭代控制协变量易化语音研究中潜在混杂效应的解释。在一些数据集中一个预测器与面孔有共同变化(Pearson的R范围:-0.55,0.57;平均值:0.18),但不出现在其他数据集。例如,在控制了语音后,我们在17个数据集中观察到面部呈现和右侧FFA活动之间的关联(图5;峰值z=5.70),尽管这种关系的强度仍然比传统的面部定位任务所预期的强度要弱。在电影中,面孔感知涉及重复和长期的一组相对狭窄的个人面孔。鉴于类别选择性功能磁共振成像反应的快速适应单个刺激的依据,自然刺激中的FFA激活减弱可能短暂过程(如初始编码)产生的面部信息区分减少。在控制了人脸适应后,我们在右侧FFA中观察到更强的效果(图5;峰值z=7.35),突出了其对面部呈现动态特征的敏感性,这是传统设计不能总是能捕捉到的。值得注意的是,与传统的定位任务不同,我们仍然观察到FFA之外的显著激活,这些区域与面孔感知的关系可以在未来使用Neuroscout的丰富特征集进一步探索。
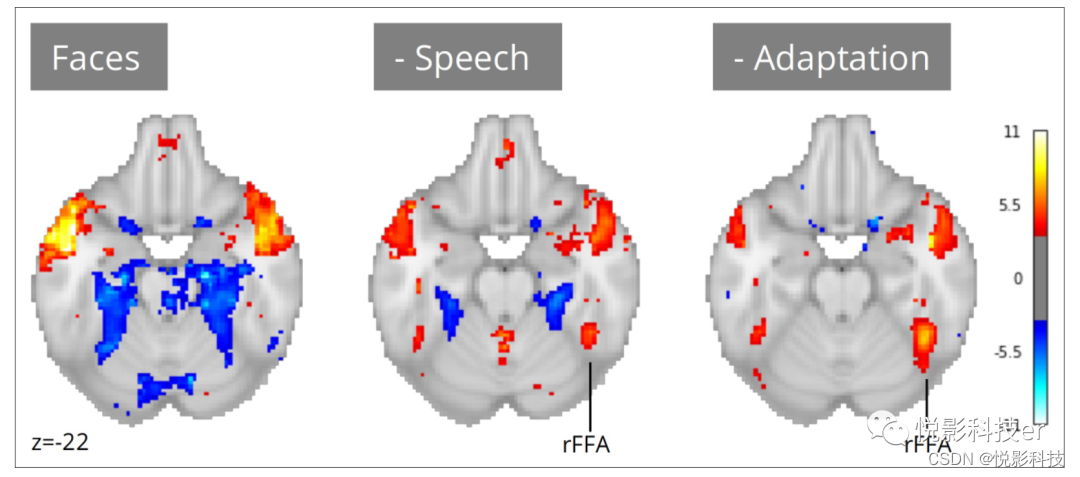
图5.使用迭代添加协变量对面部感知的元分析。左;只有包括编码屏幕上面孔的二进制预测器,没有显示右侧梭状面部区域(rFFA)的活动。中间;控制语音消除了虚假的激活,并显示了rFFA与面部呈现的关联。对;控制除言语外的对面孔身份的时间适应进一步加强了rFFA和面部呈现之间的联系。采用17个数据集;图像的阈值为Z=3.29(p<0.001)体素级。
2.4 大样本满足不同的刺激:一个语言案例研究
在一个自然的快速系列视觉呈现 ( a naturalistic rapid serial visual presentation,RSVP) 阅读实验中,Yarkoni等人,2008年报告了一个有趣的偶然结果:视觉词形式区域 (the visual word form area,VWFA,主要与视觉特征检测和正字法-音位映射相关的区域) 的活动受到词汇频率的显著调节。有趣的是,这些协变量效应对语音和正字法是稳健的,这表明VWFA活动可能不仅参与其中正字法和语音阅读的子过程,但也受到语言输入的形态独立的词汇-语义属性的调节。然而, 由于该实验只涉及语言刺激的视觉呈现,这一假设无法得到实证证实。此外,作者观察到,当控制词汇的具体性时,频率效应消失了。由于这两个变量高度相关,作者推测这项研究结果不确定。Neuroscout可研究生态刺激中的语言假设,使用广泛的语言注释来重新评估跨越语音/正字法单词属性的语言注释(e.g.持续时间和语音的特殊性),语义描述符(例如。效价、具体性、感觉运动属性) 和语言序列的高级信息理论属性。下一个单词预测和逐字突现)。我们在所有Neuroscout数据集中重新实现了Yarkoni等人2008年数据集的分析模型,包括控制单词频率、具体性、语音和正字法测量 (音节数、音素数量和持续时间) 作为回归变量, 以及一组标准的协变量参数。与之前一样,我们使用IBMA来计算每个变量的元分析估计值。所得到的脑地图在频率和具体性方面都显示了显著的VWFA效应 (图5) ,证实了其独立于呈现方式的词汇处理的假设,并且可以说是在语言到图像映射的过程中产生。因此,通过利用更大的参与者样本和更多样化的刺激,元分析克服了导致数据集水平结果不稳定的一些限制。
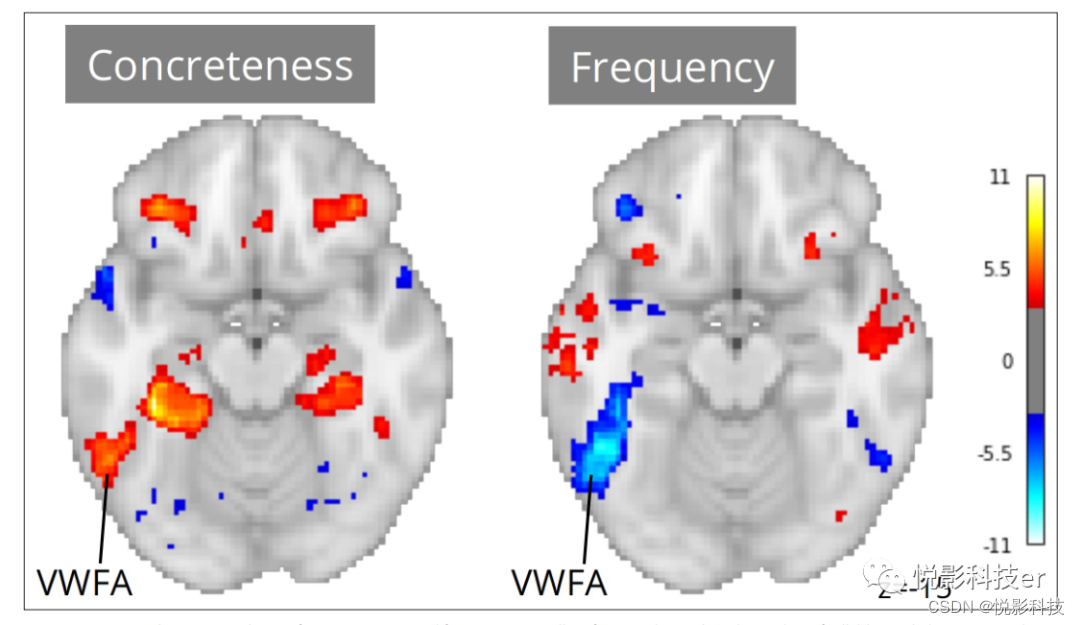
图6. 控制语音、文本长度、音节和音素数量以及phone-level Levenshtein distance后具体性和频率控制的元分析统计图。N=33个任务;图像的体素级阈值为Z=3.29 (p<0.001)。VWFA视觉词形式区域。
3.讨论
Neuroscout旨在推广采用和促进可重复性的功能磁共振成像研究实践,允许用户使用自动提取的神经预测器轻松地在几十个开放的自然数据集中测试广泛性假设。该平台的设计非常注重再现性,为功能磁共振分析提供了一个统一的框架,减少了可重复的功能磁共振分析的负担,并促进了模型和统计结果的传播透明化。由于其高度的自动化程度,Neuroscout还促进了元分析工作流的使用,使研究人员能够跨多个数据集测试他们的模型的鲁棒性和通用性。Neuroscout的模型构建器可以轻松在线访问,Neuroscout工作流适用于任何符合BIDS的数据集,对非自然研究的功能磁共振成像数据集还在完善中。其他重要的扩展包括通过直接集成于云神经科学分析平台来促进分析执行,如https://brainlife.io/about/, 以及通过集成MechanicalTurk or Prolific等众平台来促进更高级别的刺激特征的收集。
此外,随着Neuroscout的发展,促进更广的公共数据集的重新分析,还要考虑到重复导致“数据集衰减” 的威胁。解决的办法为鼓励所有尝试性分析和相关性结果中心注册,Neuroscout被设计成最小化未记录的研究人员的自由度,并将最终发表的结果与之前的所有尝试联系起来。Neuroscout鼓励公众分享所有的结果,鼓励元科学家实证地研究数据集衰减问题的统计解决方案,并开发出最小化假阳性影响的方法。
4.方法
4.1 代码
所有的处理流程和Neuroscout核心基础设施的代码都可以在线获得(https://www.github.com/neuroscout/neuroscout; Alejandro de la, 2022a), 包括Python client library pyNS (https://www.github.com/neuroscout/pyNS; Alejandro de la, 2022b). Neuroscout-CLI分析引擎可以作为Docker和奇点容器使用,源代码也可用 (https://github.com/neuroscout/neuroscout-cli/)。最后,在本文中展示的分析在线补充 Jupyter Book (https://neuroscout.github.io/neuroscout-paper/)。所有这些产品都可以在许可的BSD许可下提供。
4.2 数据库
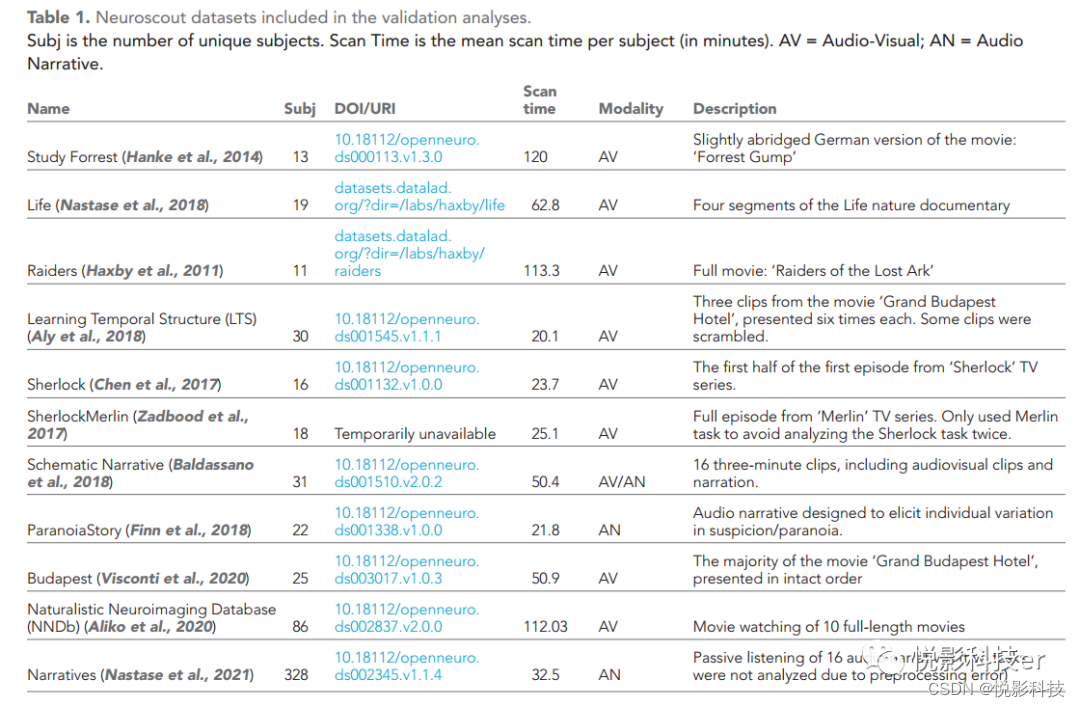
本文中提出的分析是基于来自各种开放数据存储库的13个自然主义的fMRI数据集 (见表1) 。数据集使用pybids (https://github.com/bids-standard/pybids),并将其纳入SQL数据库进行后续分析。几个数据集跨越了各种原始研究或不同的模拟,提供35个独特tasks或‘studies’可供分析。完整的数据集列表和他们可用的预测器可以在(https://neuroscout.org/datasets)获取。
4.3 fMRI预处理
使用fmriprep (版本1.2.2) 对Neuroscout数据集进行统一预处理,所得到的预处理数据可以公开下载 (https://github.com/neuroscout-datasets) 。
4.4 自动提取的特征
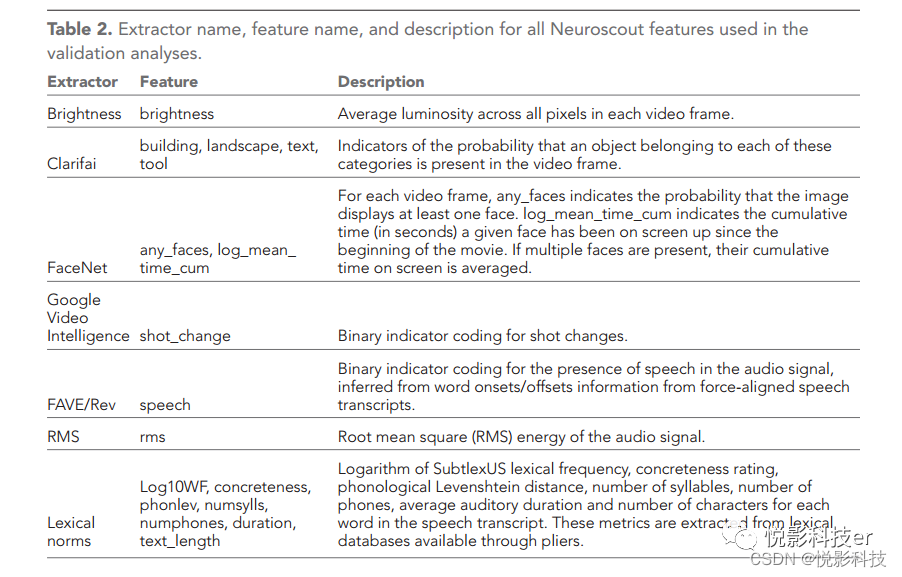
Neuroscout员利用最先进的机器学习算法, 自动从原始的实验刺激中提取数百个新的神经预测器。自动特征提取依赖于pliers,一个用于多模态特征提取的python库,它为多种机器学习算法和api提供了一 个标准化的接口。特性值被直接摄入,除了将高密度变量降采样到3 Hz,以方便在服务器上存储,没有进行其他的修改。对于本文中报告的所有分析,在所有数据集上都应用了相同的特征提取器集 (见表2) ,除非模态不匹配而不可能出现的特征(例如在音频叙事中的视觉特征),或在刺激中本质上不存在的特征(e.g.自然纪录片中的面孔)。下面描述了本文中所包含的所有特征。
4.5 GLM模型
Neutoscout使用FitLins这种新开发的工作流程,用于执行由bid状态模型规范定义的多层fMRI一般线性模型 (GLM) 分析。FitLins使用pybids生成运行级设计矩阵,并使用NiPype封装多级GLM工作流。被试内的模型估计使用AFNI进行,而受试者和组级的汇总统计数据使用 nilearn.glm模块进行拟合。对于所有的模型,除了列出的感兴趣的特性外,还包含了来自fmriprep的一组标准的混杂因素。该集合包括6个运动校正参数,6个使用CompCor计算的噪声分量,一个余弦漂移模型,和可能存在的非稳态体积检测。使用pybids将回归变量与SPM色散导数血流动力学响应模型进行卷积,并计算出一级设计矩阵并降采样到TR。使用一个标准的AR (1) +噪声模型将设计矩阵拟合到非平滑的配准图像上。利用4 mm FWHM isotropic kernel对所得的参数估计图像进行平滑处理。对于每个受试者有多次运行的数据集,用平滑后运行参数估计作为输入,拟合一个受试者水平的固定效应模型,从而得到每个回归变量的受试者水平参数估计。最后,我们使用被试内水平的参数估计值拟合了一个组水平的固定效应模型,并对模型中的每个回归变量进行了单样本t检验对比。
4.6 元分析
Neutoscout数据集进行荟萃分析采用NiMARE(版本0.0.11rc1;可在:https://github.com/neurostuff/NiMARE;RRID:SCR_017398)。典型的研究步骤(平滑、设计矩阵缩放、空间归一化) 被放弃,因为所有组水平的beta和方差图都是使用相同的GLM流程生成的。所有组水平的beta和方差图被重新采样到一个2x2×2 mm ICBM 152非线性对称灰质模板 ( 使用nilearn,版本0.8.0) ,并进行线性插值。通过使用 DerSimonian & Laird random effects元回归算法,重新采样的值被裁剪到原始地图中观察到的最小和最大统计值。
参考文献:Neuroscout, a unifed platform for generalizable and reproducible fMRI research