pycharm连接虚拟机中的spark
1.打开pycharm
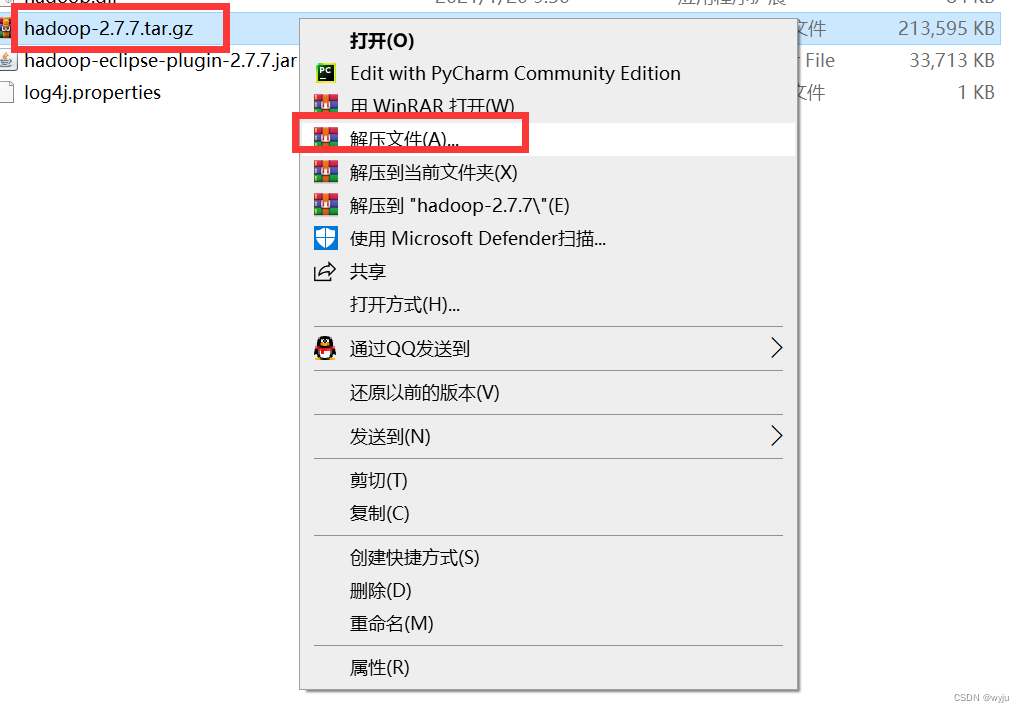
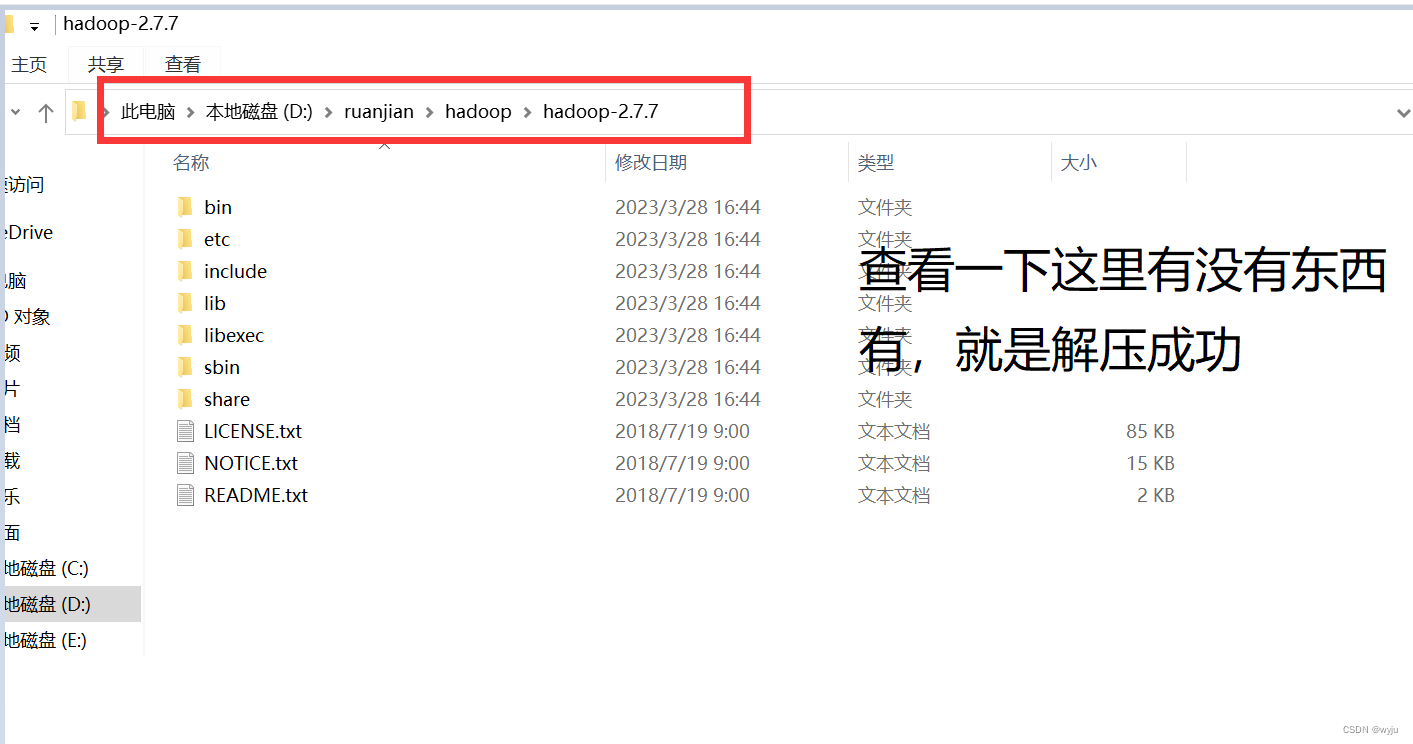
2.解压hadoop,解压到windows下面,切记不要有中文路径

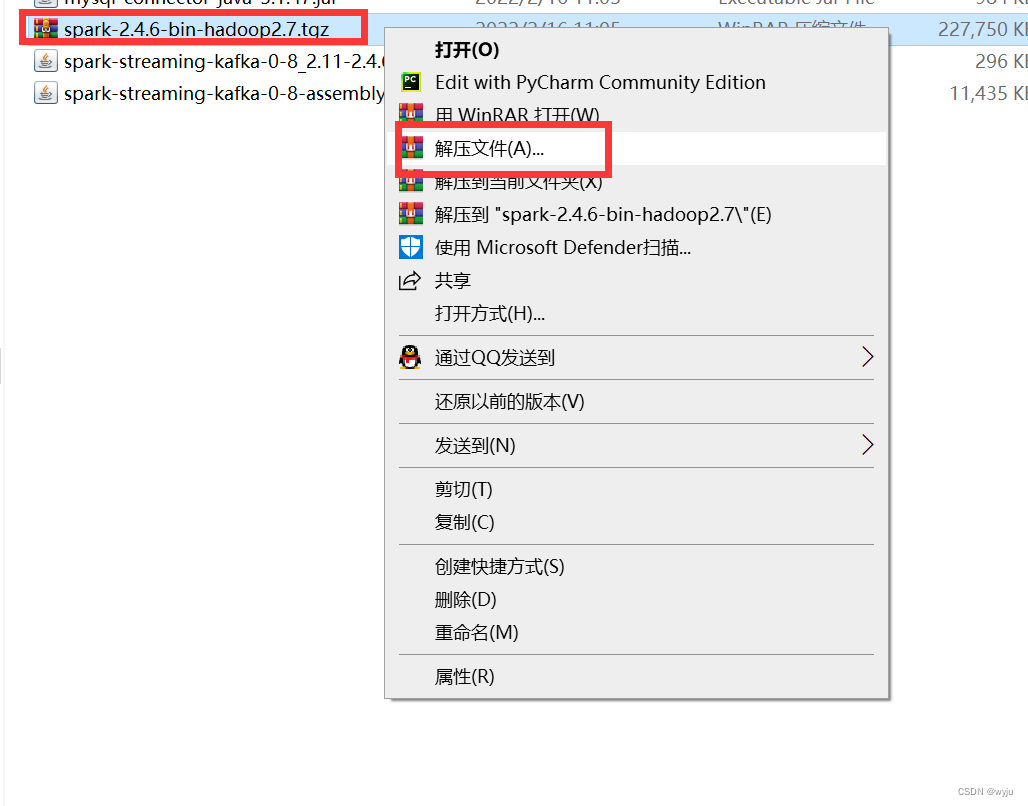
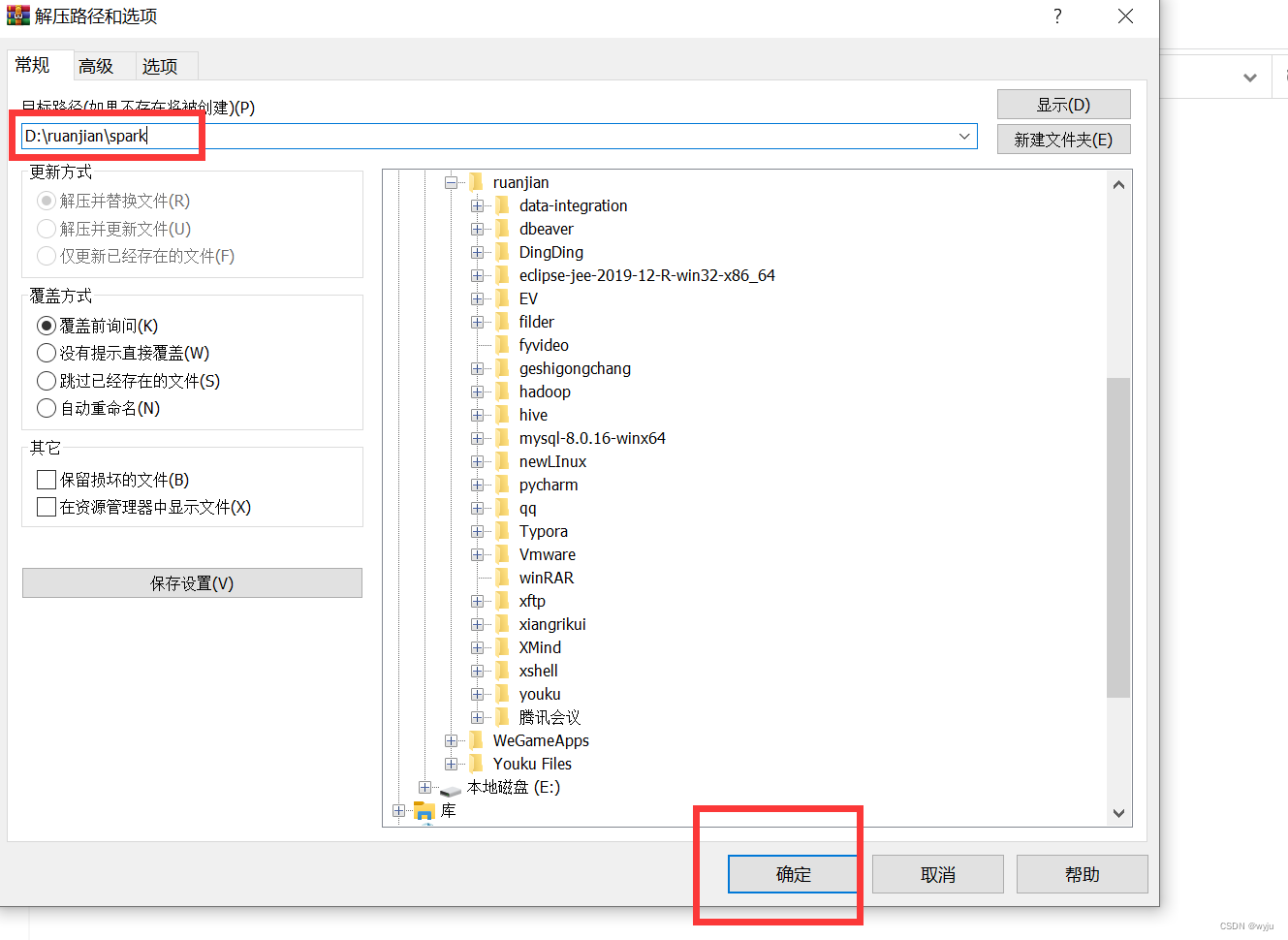
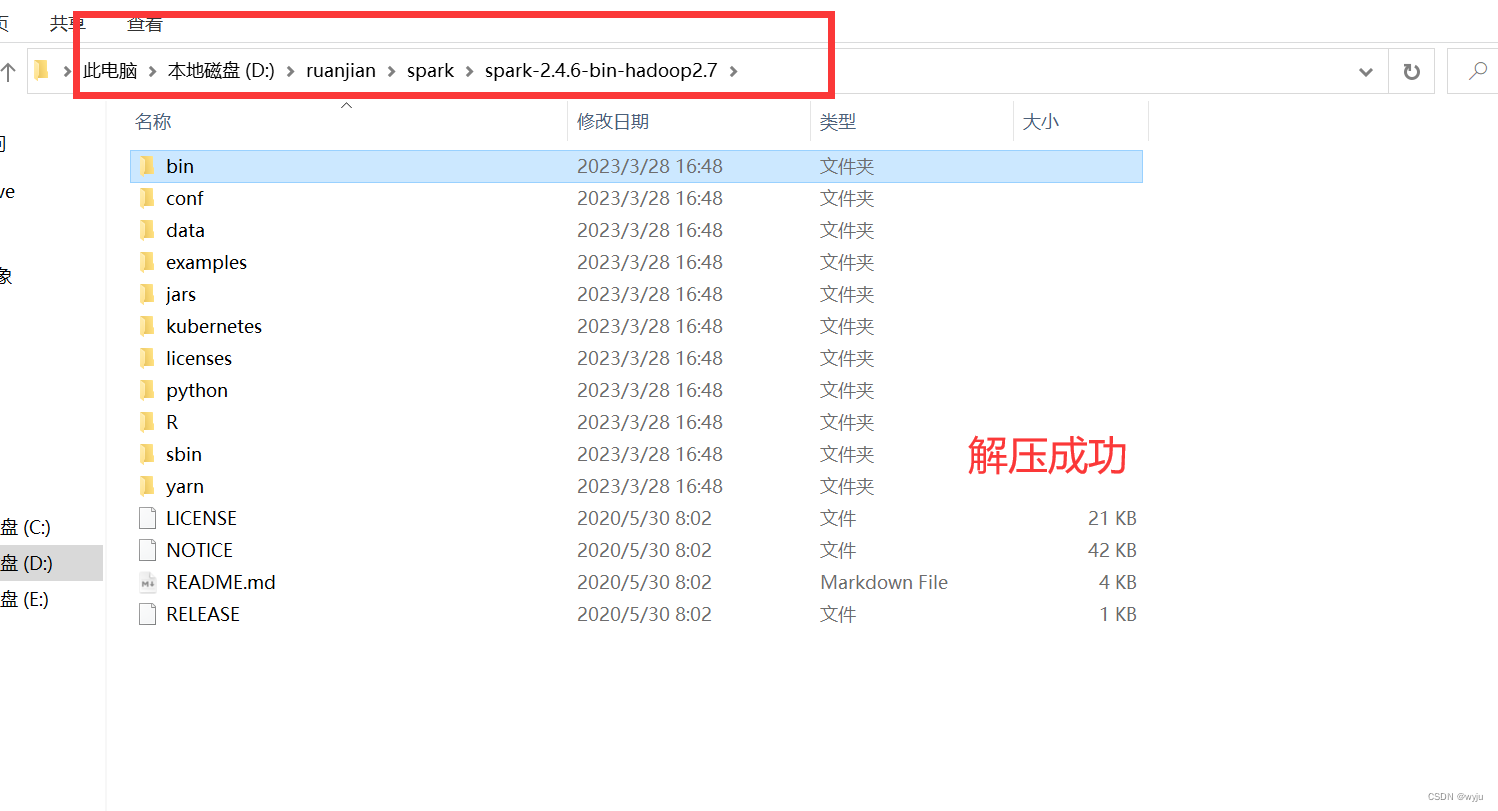
3.解压spark,解压到windows下面,切记不要有中文路径
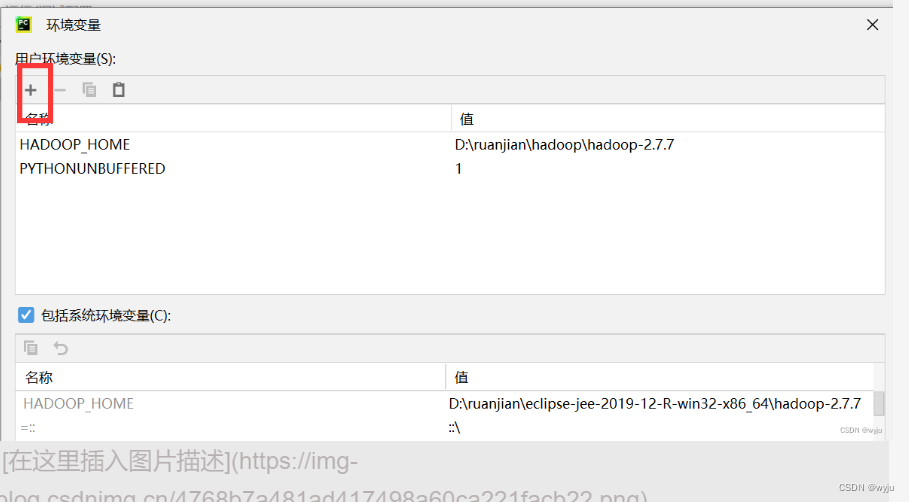
4. 把haoop,sprk对应的环境变量配置到pycharm中
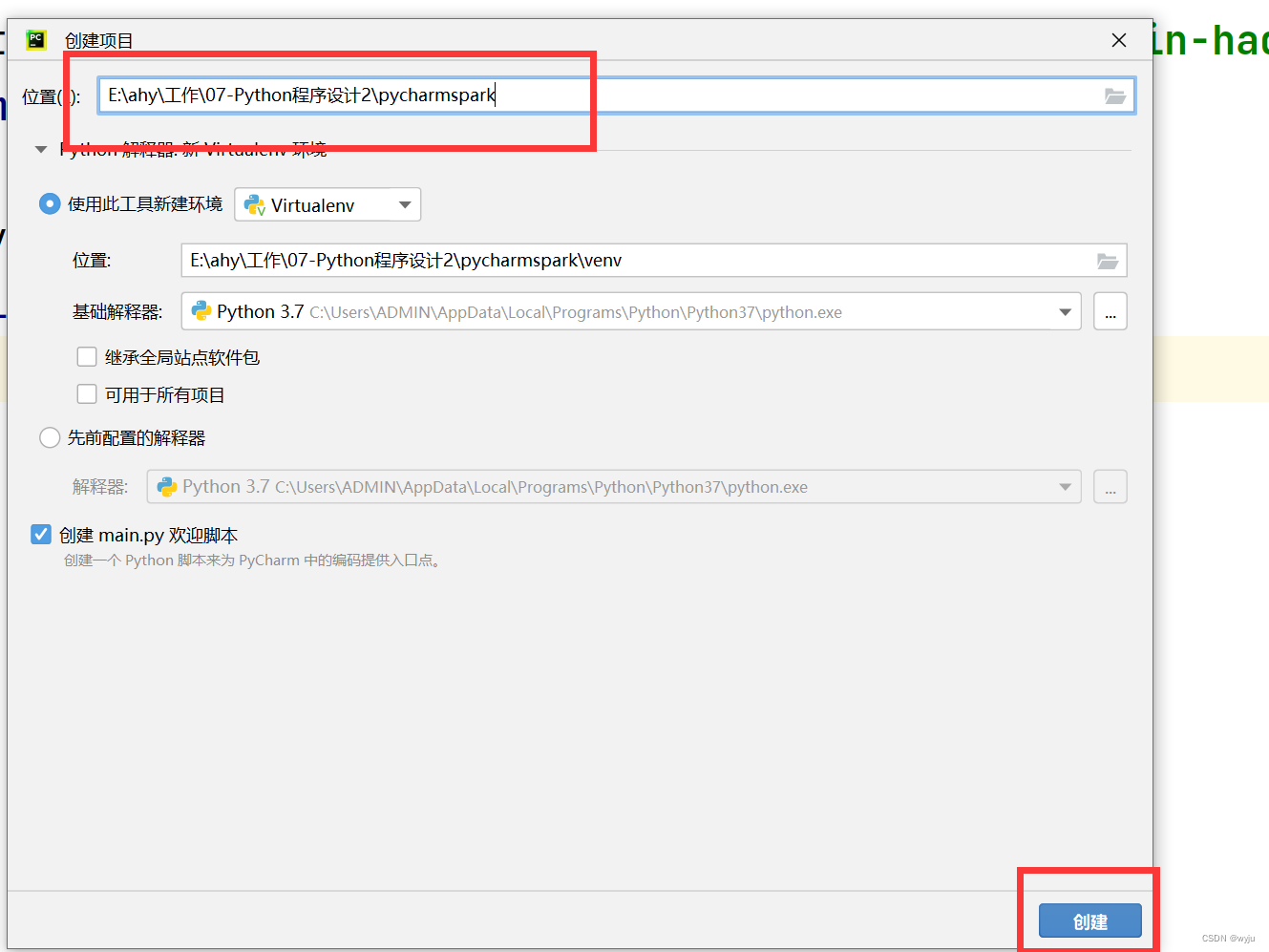
4.1新建一个项目
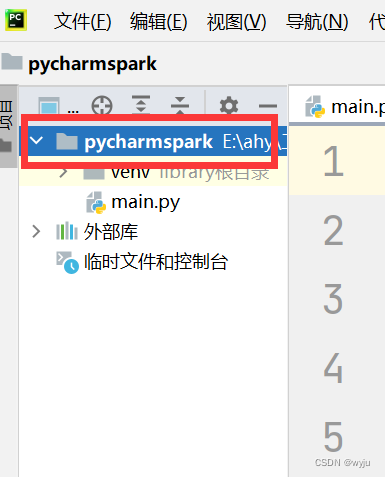
4.2在项目中新建一个python文件
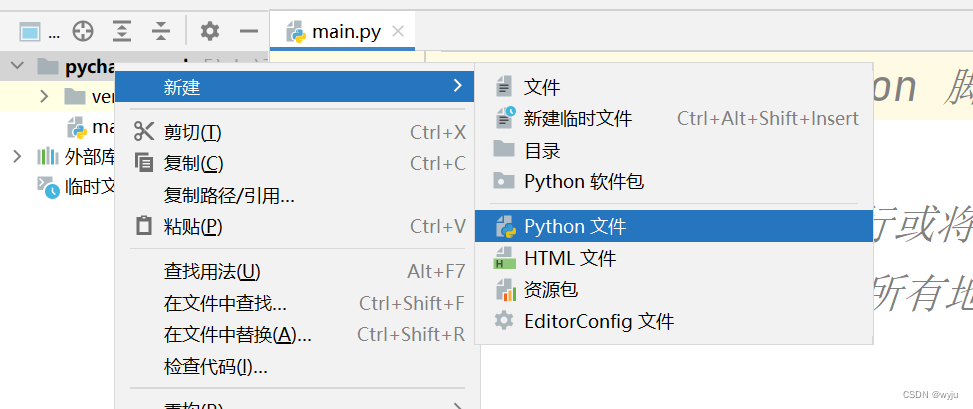
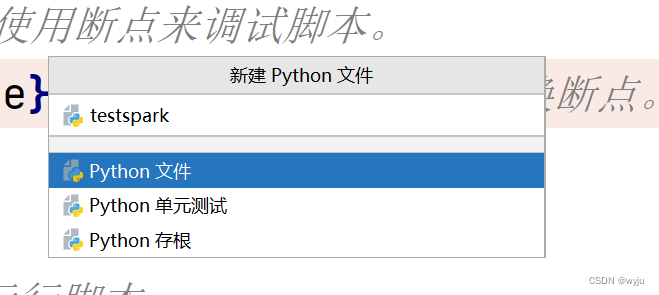
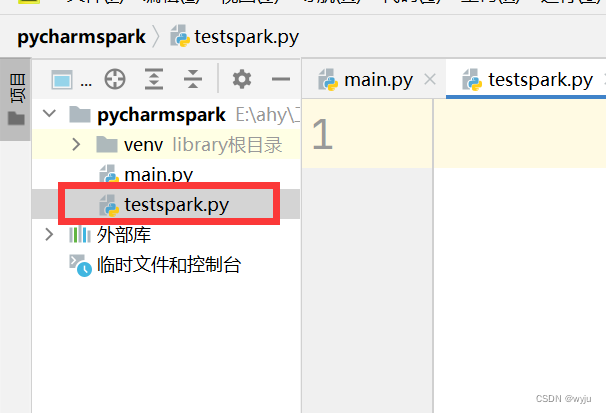
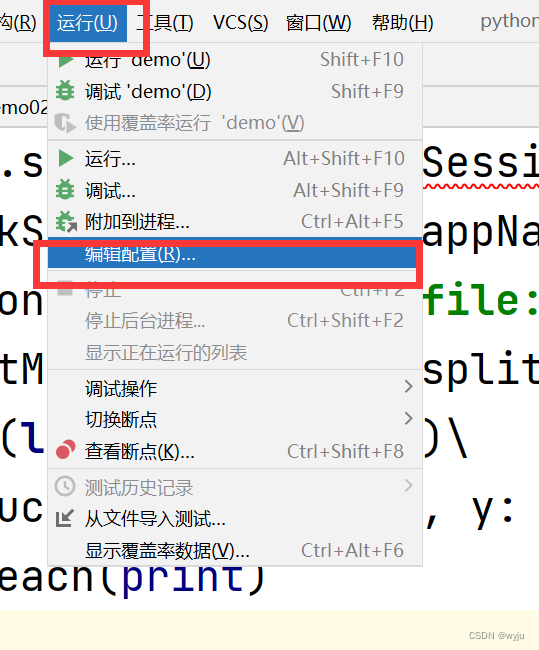
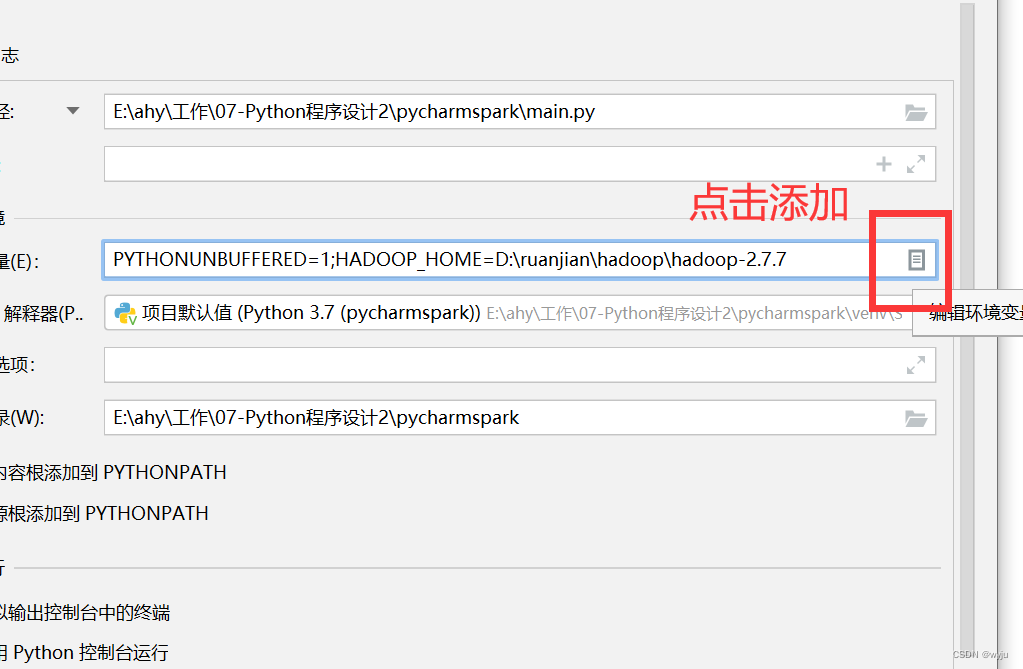
4.3把hadoop添加到pycharm中
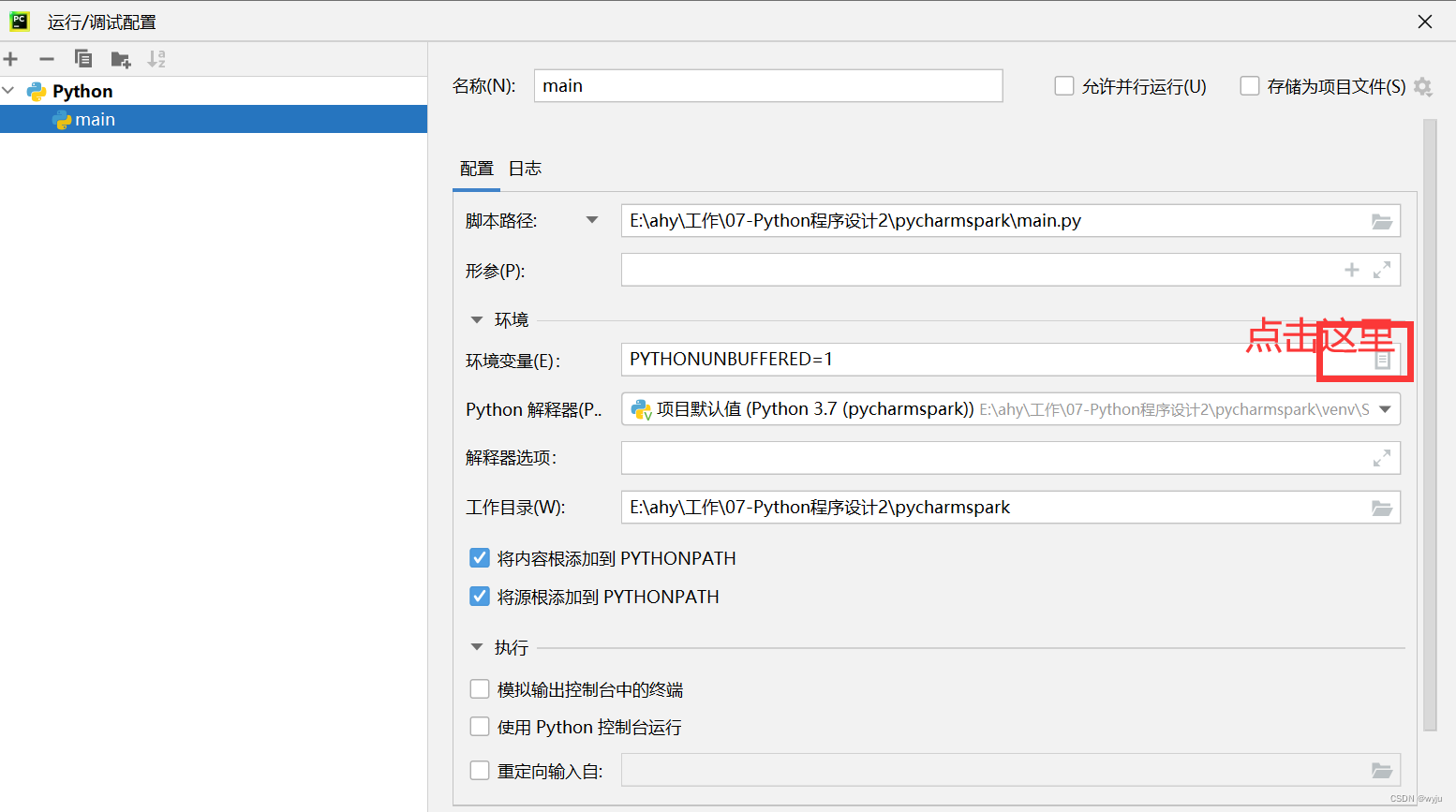
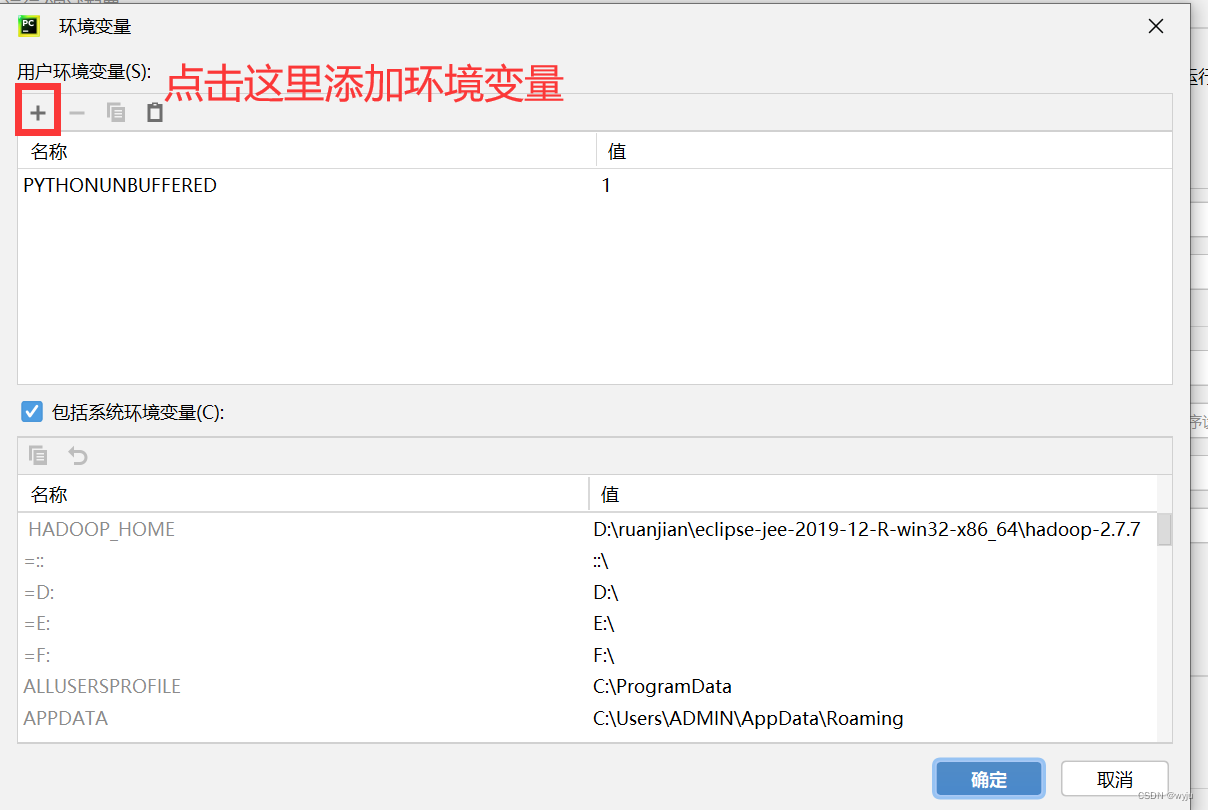
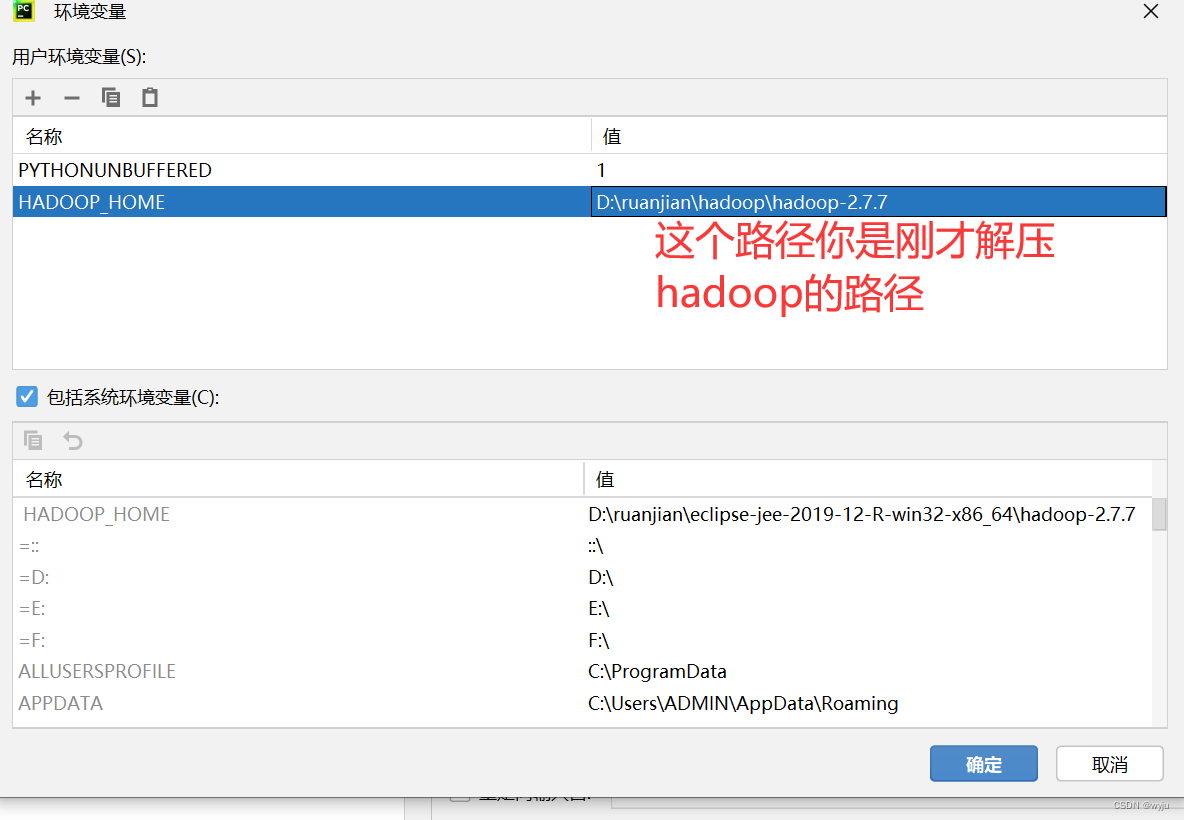
HADOOP_HOME
4.4winutils.exe 插件放到hadoop/bin下面
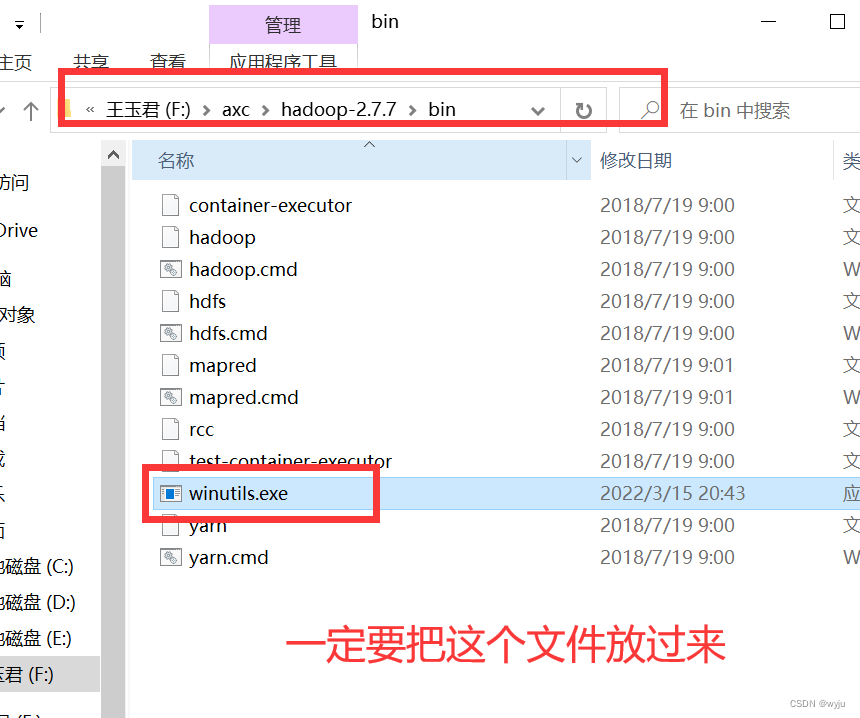
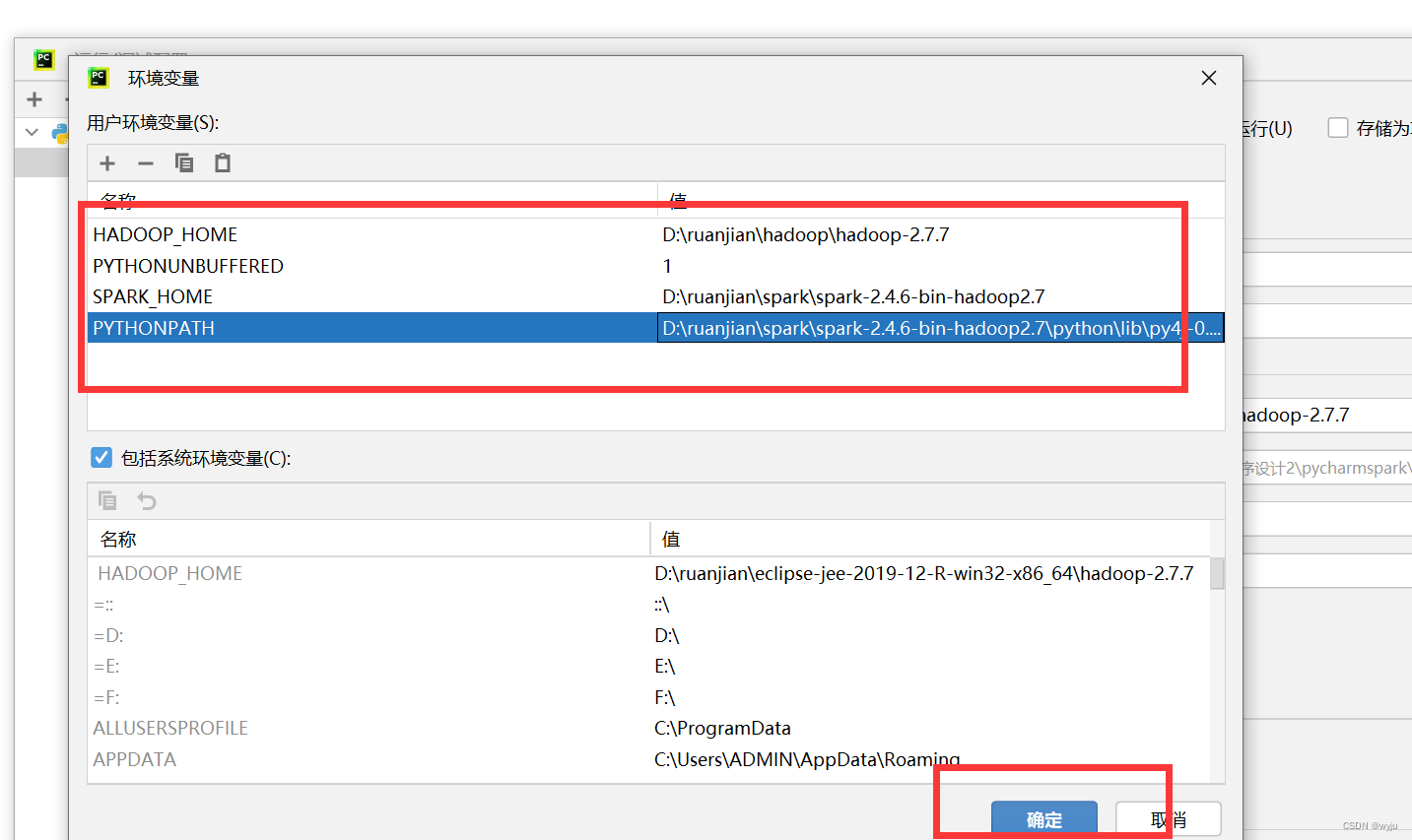
4.5把spark添加到pycharm中
SPARK_HOME、PYTHONPATH



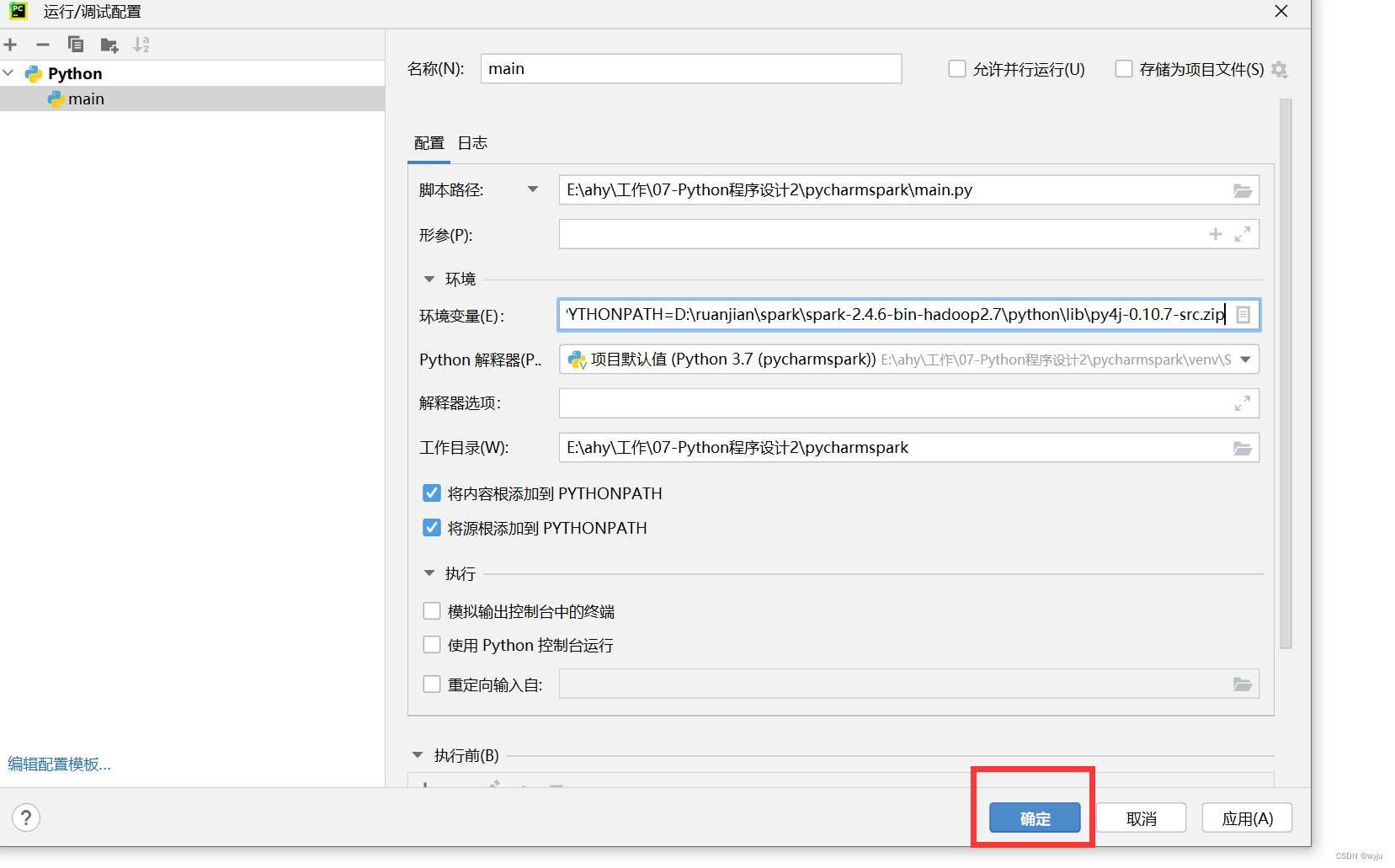
5.安装插件
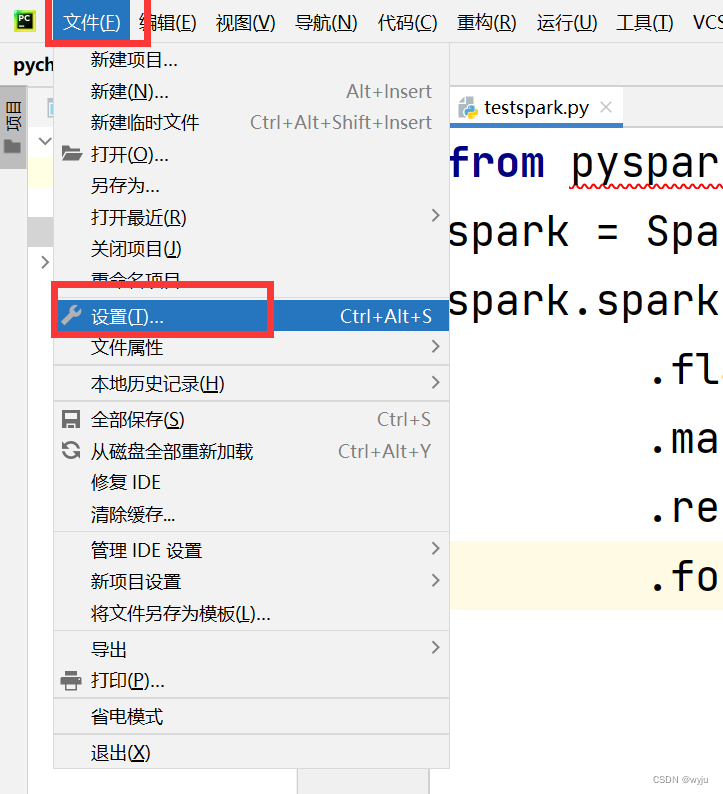
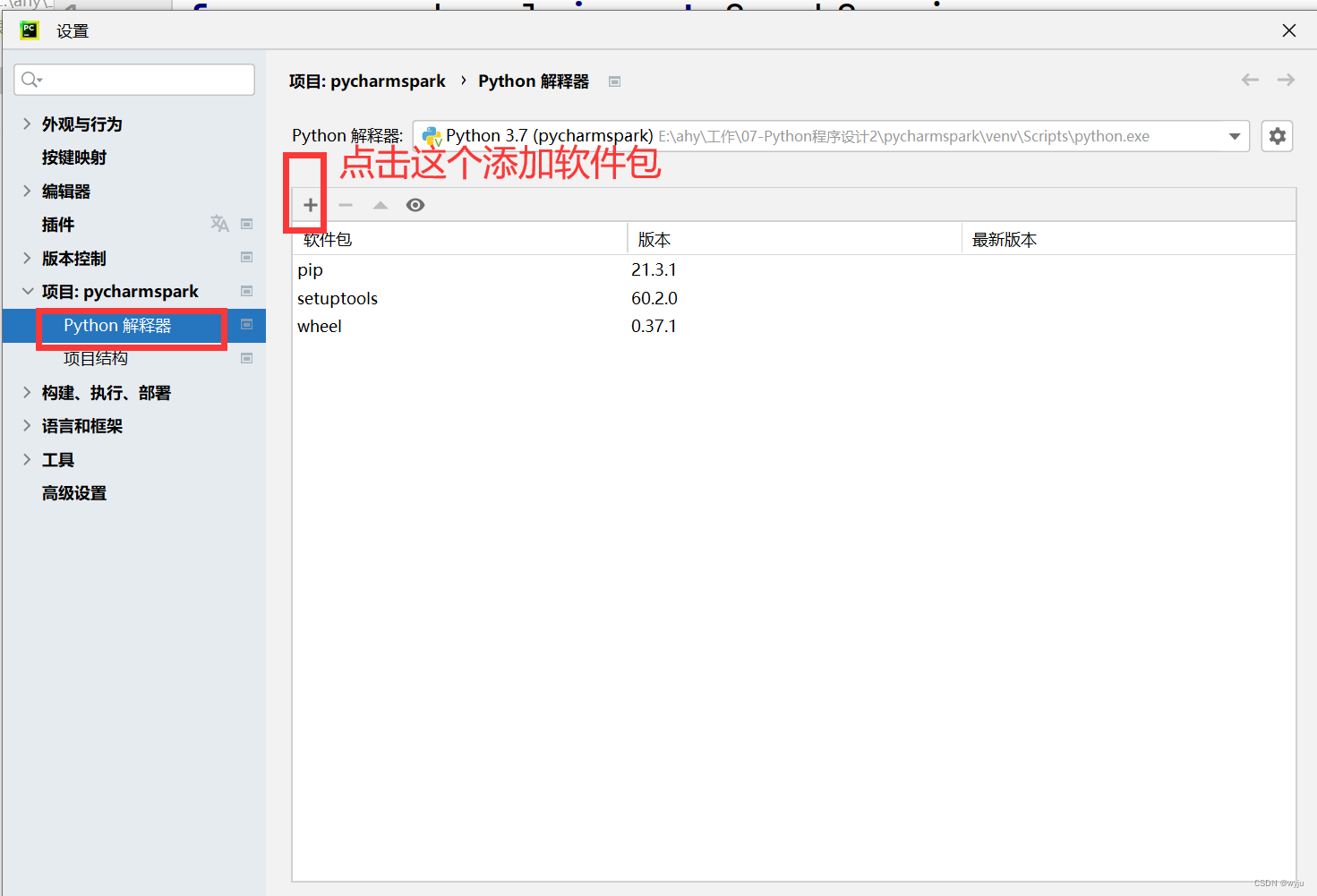
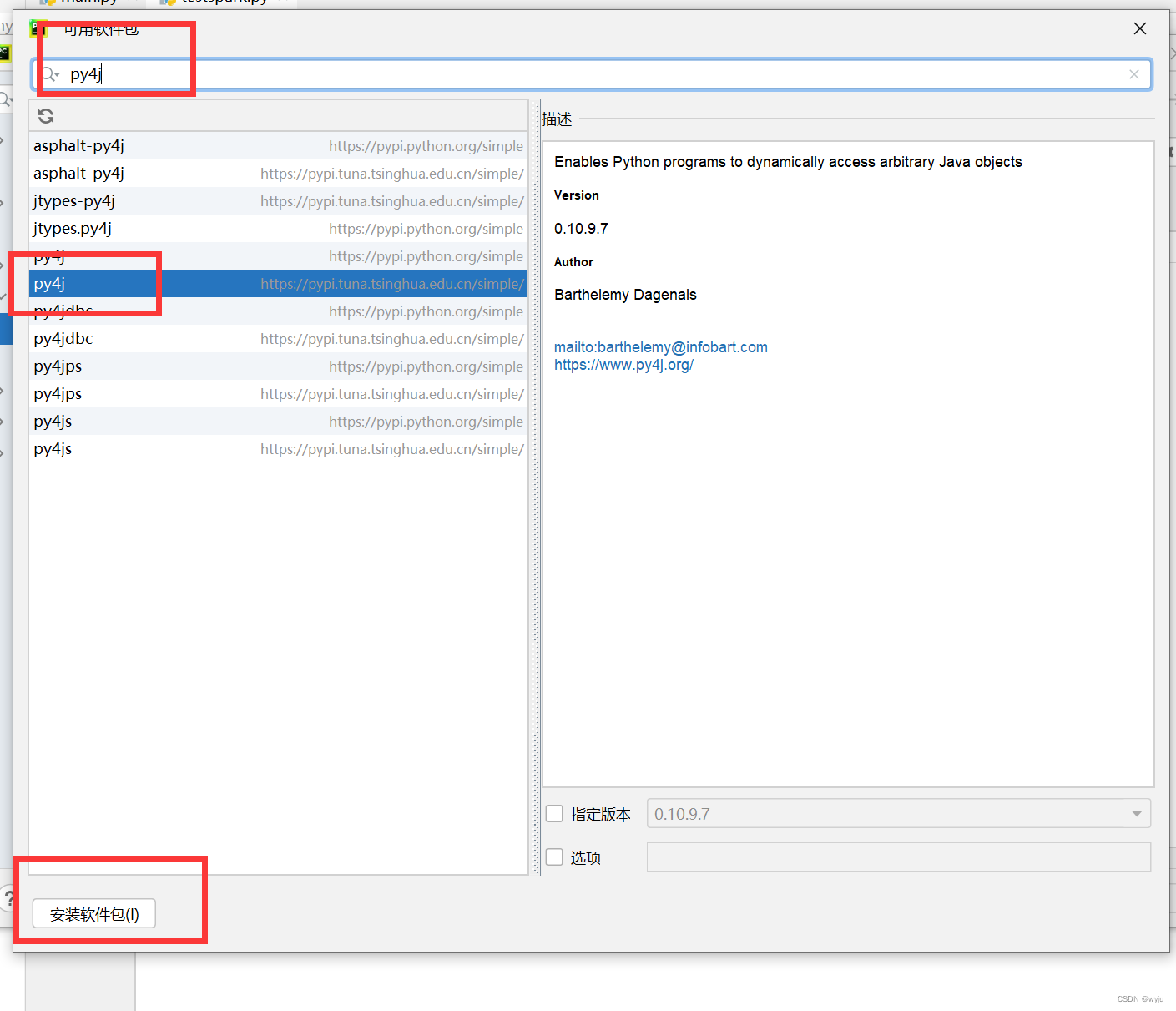
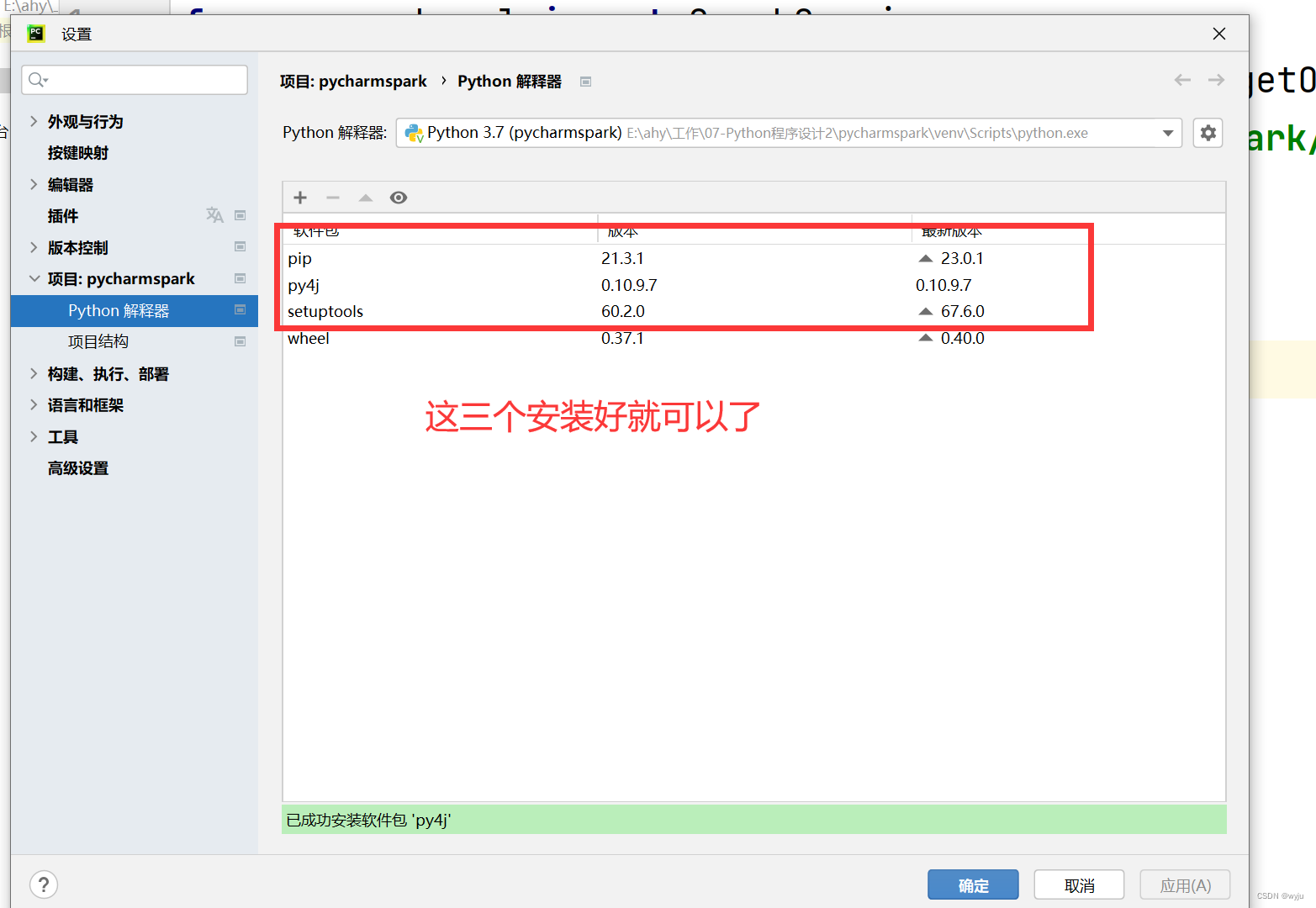
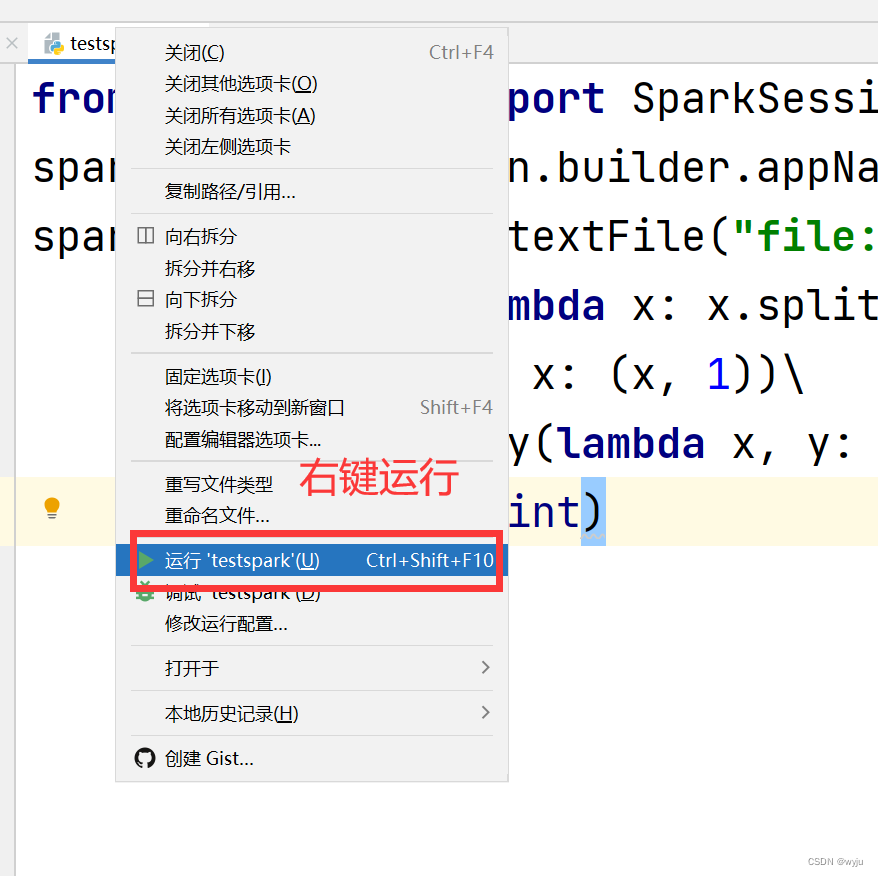
6.测试
6.1把以下代码放到我们4.2步哪里新建的testspark.py文件中
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("WordCount").getOrCreate()
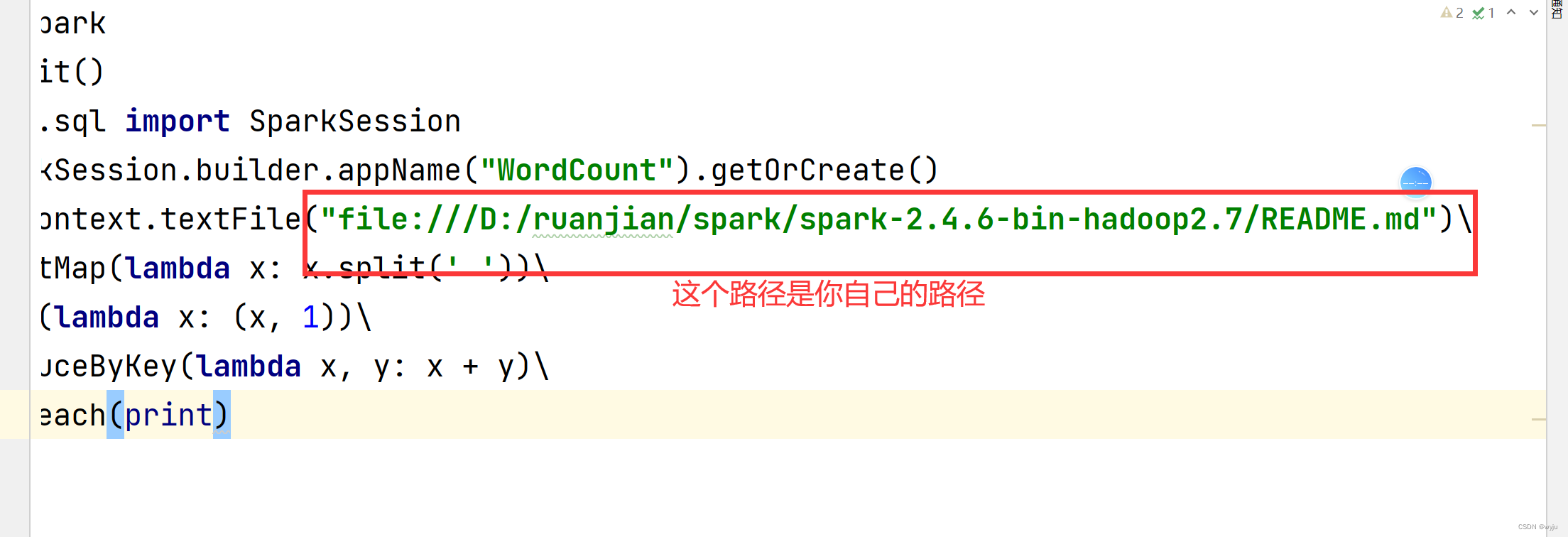
spark.sparkContext.textFile("file:///D:/ruanjian/spark/spark-2.4.6-bin-hadoop2.7/README.md")\
.flatMap(lambda x: x.split(' '))\
.map(lambda x: (x, 1))\
.reduceByKey(lambda x, y: x + y)\
.foreach(print)
注意注意注意
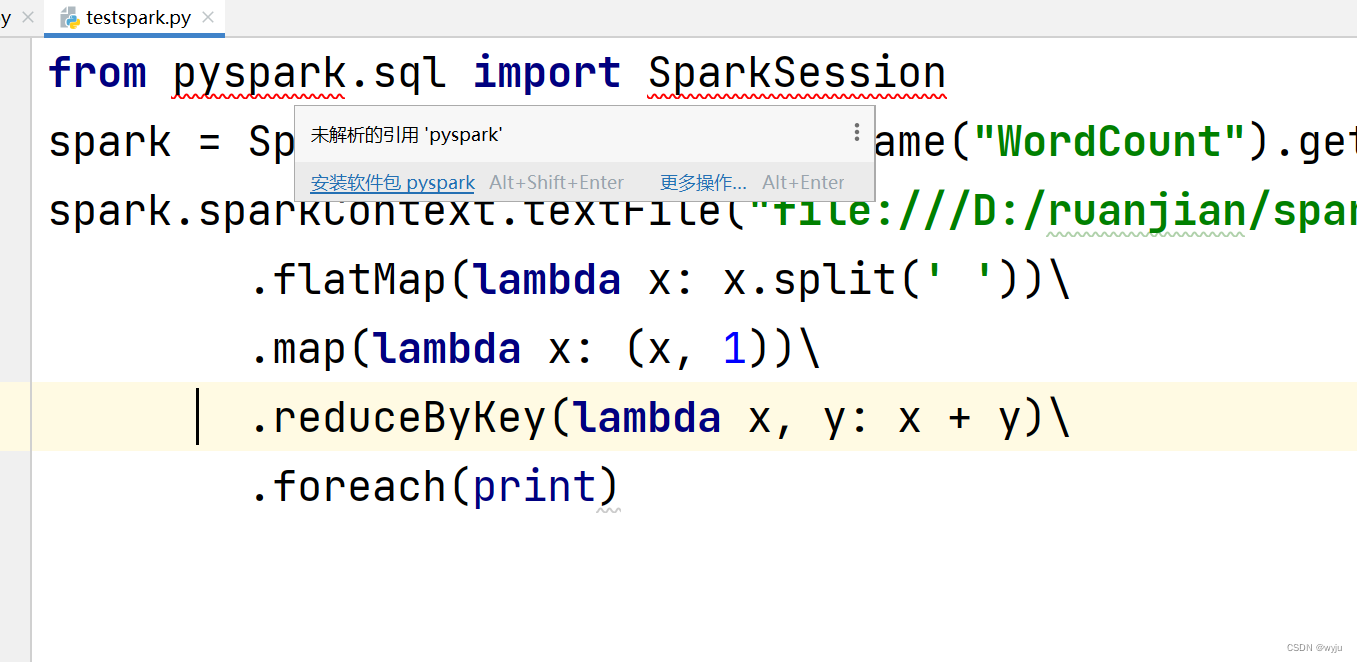
6.2 安装pyspark和findspark
6.3测试