结构体详解
🍍个人主页🍍:🔜勇敢的小牛儿🚩
🔱推荐专栏🔱:C语言知识点
⚠️座右铭⚠️:敢于尝试才有机会
🐒今日鸡汤🐒:有时候躺下是为了更好的休息。
思维导图:
目录
一,结构体的基础知识
1.1结构体类型的简单介绍:
1.2结构体类型的声明:
1.3结构体变量的定义:
1.4结构体的初始化:
1.5结构体传参:两种方式
二,结构体的自引用
2.1: 在结构体内部放一个相同的结构体?
2.2:在结构体内部放一个结构体类型的指针?
上面两种写法中,第一种写法是错误的。第一种写法就像一个递归但是没有终止条件,所以会无限循环下去。
三,结构体的内存对齐(求结构体大小)
3.1:练习
3.2:结构体节省空间的操作:
比如,第一个结构体变量s1的大小本来是12的,现在我们进行下列操作:
3.3:结构体内存对齐的原因:以空间换时间
4.结构体的位段
4.1:什么是位段:位就是二进制位。
4.2:位段内存的分配:
结束
一,结构体的基础知识
1.1结构体类型的简单介绍:
结构体是一些值的集合,这些值叫做结构体的成员。每一个成员可以是不同类型的变量。
1.2结构体类型的声明:
1.2.1,声明的通式:
struct tag// 类型为struct tag{member - list ;/ /结构体成员} variable - list ;// 变量名
例子:
struct Stu {//定义一个结构体类型来接收一个学生的个人信息
//strut Stu 是一个类型
char name[20];
char ID[12];
int age;
float weight;
};
1.3结构体变量的定义:
1.3.1:边声明边定义:定义一个全局结构体变量s1
struct Stu {
char name[20];
char ID[12];
int age;
float weight;
}s1;//定义了一个全局的结构体变量s1
1.3.2:先声明再定义:定义一个全局结构体变量s2
struct Stu {
char name[20];
char ID[12];
int age;
float weight;
};
struct Stu s2;//定义一个结构体全局变量s2
1.3.3:先声明再定义:定义一个局部结构体变量s3
struct Stu {
char name[20];
char ID[12];
int age;
float weight;
};
int main() {
struct Stu s3;//在主函数里面定义一个结构体变量,所以是个局部变量
return 0;
}
1.3.4:使用tepydef关键字重新定义再使用:
typedef struct Stu {
char name[20];
char ID[12];
int age;
float weight;
}Teacher;//此时将结构体类型struct Stu重命名为Teacher.(Teacher 此时是一个类型而不是变量)
Teacher s1;
int main() {
Teacher s2;
return 0;
}
1.4结构体的初始化:
1.4.1:像数组一样初始化:带个大括号然后按顺序初始化
struct Stu {
char name[20];
char ID[12];
int age;
float weight;
}s1;
s1 = { "zhang san","1357924",20,45.9f };//初始化内嵌一个结构体:
struct people {
char name[20];
int age;
};
struct Stu {
char name[20];
char ID[12];
struct people s2;
int age;
float weight;
};
struct Stu s1 = { "zhang san","1357924",{"lishi",25},20,45.9f};//初始化
1.4.2:使用.操作符,不按顺序初始化.
struct Stu s1 = { .name = "zhang san",.weight = 46.9f,.ID = "1357924", .s2 = {"lishi",25},.age = 20};//初始化1.5结构体传参:两种方式
1.5.1:值传参
将结构体变量的所有值传到一个函数里。有明显的缺点:
1.结构体变量的大小可能很大,造成空间的浪费。
2.传过去的值被形参接受以后相当于一份临时拷贝,修改形参的值不能达到修改实参的效果。
1.5.2:址传参
顾名思义传到函数里面的是结构体的地址,址传参可以将形参与实参联系到一起。可以通过改形参来改实参。而且,传址的效率更高。
二,结构体的自引用
结构体的自引用就是自己引用自己,就是在一个结构体内部引用一个相同类型的结构体变量。那结构体应该怎样引用自己呢?
2.1: 在结构体内部放一个相同的结构体?
struct Node {//声明一个结构体
int data;
struct Node next;//在结构体内部自引用自己
};2.2:在结构体内部放一个结构体类型的指针?
struct Node {//声明一个结构体
int data;
struct Node* next;//在结构体内部自引用自己
};上面两种写法中,第一种写法是错误的。第一种写法就像一个递归但是没有终止条件,所以会无限循环下去。
三,结构体的内存对齐(求结构体大小)
规则:
1. 第一个成员在与结构体变量偏移量为0的地址处。2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。VS中默认的值为83. 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
3.1:练习
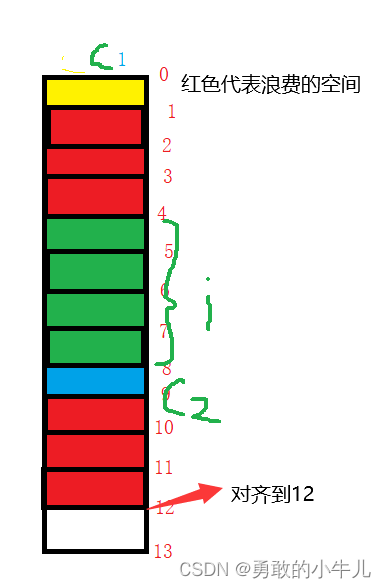
3.1.1:
#include<stdio.h>
struct S1 {
char c1;
int i;
char c2;
};
int main() {
printf("%d\n", sizeof(struct S1));
}
输出:12
解释:
因为i的变量大小为4个字节,所以i的对齐数为4,所以在C1占据一个字节时要浪费3个字节使i对齐到4。因为默认对齐数为8,结构体成员最大的元素为i有4个元素,所以这个结构体的大小要为4的倍数,满足条件的最小的4的倍数为12,所以结构体大小为12个字节。
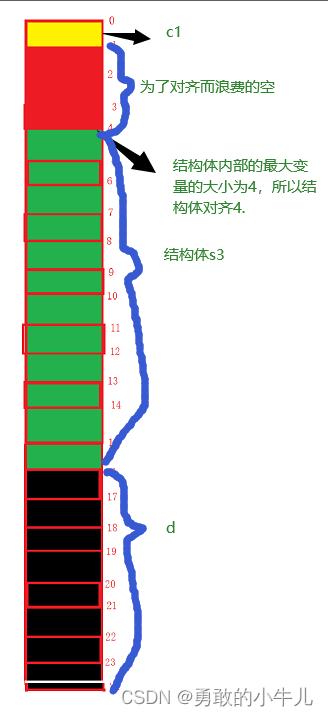
3.1.2:结构体嵌套:
#include<stdio.h>
struct S1 {
char c1;
int i;
char c2;
};
struct S2
{
char c1;
struct S1 s3;
double d;
};
int main() {
printf("%d\n", sizeof(struct S2));
return 0;
}输出:24
解释:
4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整 体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
#include<stdio.h>
struct S1 {
char c1;//1
int i;//4
char c2;//1
};
struct S2
{
char c1;//1
struct S1 s3;//12
double d;//8
};
int main() {
printf("%d\n", sizeof(struct S2));
return 0;
}
3.2:结构体节省空间的操作:
让占用空间小的变量聚集在一起
比如,第一个结构体变量s1的大小本来是12的,现在我们进行下列操作:
#include<stdio.h>
struct S1 {
char c1;//将c1与c2放在一起
char c2;
int i;
};
int main() {
printf("%d\n", sizeof(struct S1));
}输出:8
3.3:结构体内存对齐的原因:以空间换时间
4.结构体的位段
4.1:什么是位段:位就是二进制位。
这就是位段:
struct A
{
int _a:2;
int _b:5;
int _c:10;
int _d:30;
};位段的声明与结构体相似,但是有两个不同:
1.位段的成员必须是int,unsigned int,signed int型。
2.位段的成员名后边有一个冒号和一个数字。
4.2:位段内存的分配:
位段的内存是按4个字节和1个字节两种方式来分配的。
1.当成员为int类型的时候就按4个字节来分配。
2.当成员为char型(也是int型)时就按一个字节来分配。
4.2.1:练习:
#include<stdio.h>
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main() {
struct A a;
printf("%d\n", sizeof(a));
return 0;
}输出:8
解释:
#include<stdio.h>
struct A
{
int _a : 2;//2个比特位
int _b : 5;//5个比特位
int _c : 10;//10个比特位
int _d : 30;//30个比特位
};//共47个比特位
int main() {
struct A a;
printf("%d\n", sizeof(a));//因为是int型,
//所以先分配4个字节的空间也就是32个比特位
//但是不够,所以还要分配4个比特位。一共分配了8个比特位。
return 0;
}