程序编译的过程
一个程序是怎么变成可执行程序的?程序编译有哪些过程?都做了些什么事?
文章目录
- 预处理 / 预编译
- 编译
- 汇编
- 链接
- 总结
预处理 / 预编译
源文件的编译有三个小过程,预处理,编译,汇编。最后经过链接,生成可执行程序。这如果细细地讲,那就是大学中的一门课《编译原理》,这是大学中最难的一门课之一。这里讲的没有那么细,但是也绝对够用了。
下面在Linux上演示各个过程,先随便写一点代码
观察预编译,使用下面的指令生成预编译之后的文件


下面进入预编译之后的文件,看看发生了什么。
足足多了八百多行,并且包含的头文件没有了,取而代之的是一个文件地址,我们尝试打开这个文件。

打开之后可以发现除了注释,其他基本上就和.i文件中多出的内容是一样的,这里就不再进行展示对比了。
并且我们还可以发现,除了展开头文件,还删除和注释和把宏替换为了指定的符号或者数字。
所以,我们就可以总结,编译阶段基本上是做了三件事:
- 头文件的展开
- 注释的删除
- 宏替换
所以说,在预处理阶段完成的都是文本替换.
编译
输入下面的指令,可以将 .i 或者 .c 文件生成为编译后的文件,即.s文件。
进入.s文件
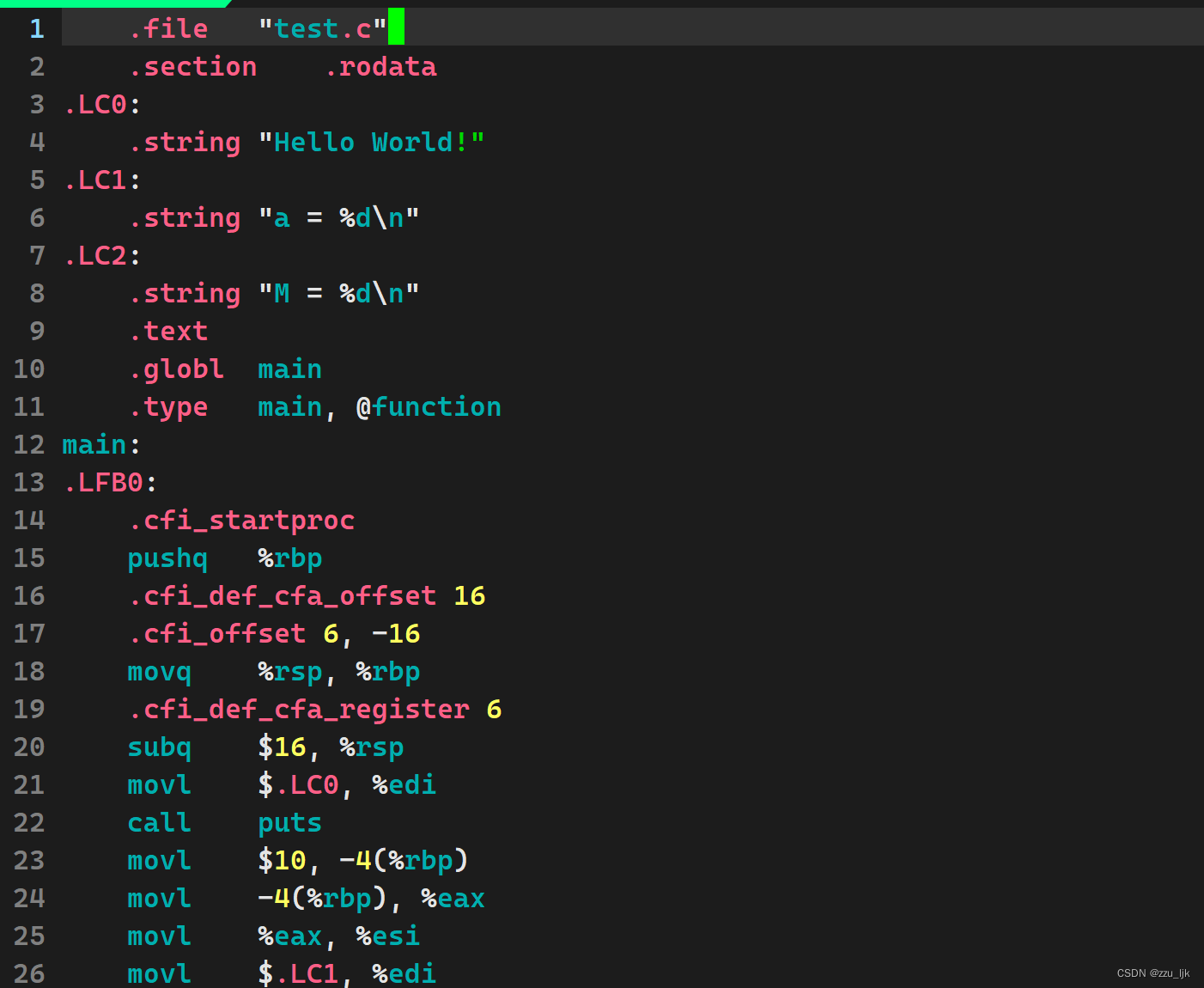
可以发现都是一些看不懂的汇编指令,所以我们也就可以清楚,在编译阶段,编译器将C语言代码转换为了汇编代码。
但是这个转换是非常复杂的,实际上做了四件事:语法分析,词法分析,符号汇总,语义分析。
这个符号汇总得说一下,后续在链接阶段用得到。
那么会对哪些符号进行汇总呢?其实也就那么几个。
全局变量,函数名。而局部的变量不会进行汇总,原因是局部变量在程序运行之后才进行创建,所以此时其实他们还并不存在。这就是符号汇总。
汇编
执行下面指令,进行汇编。
打开 .o 文件
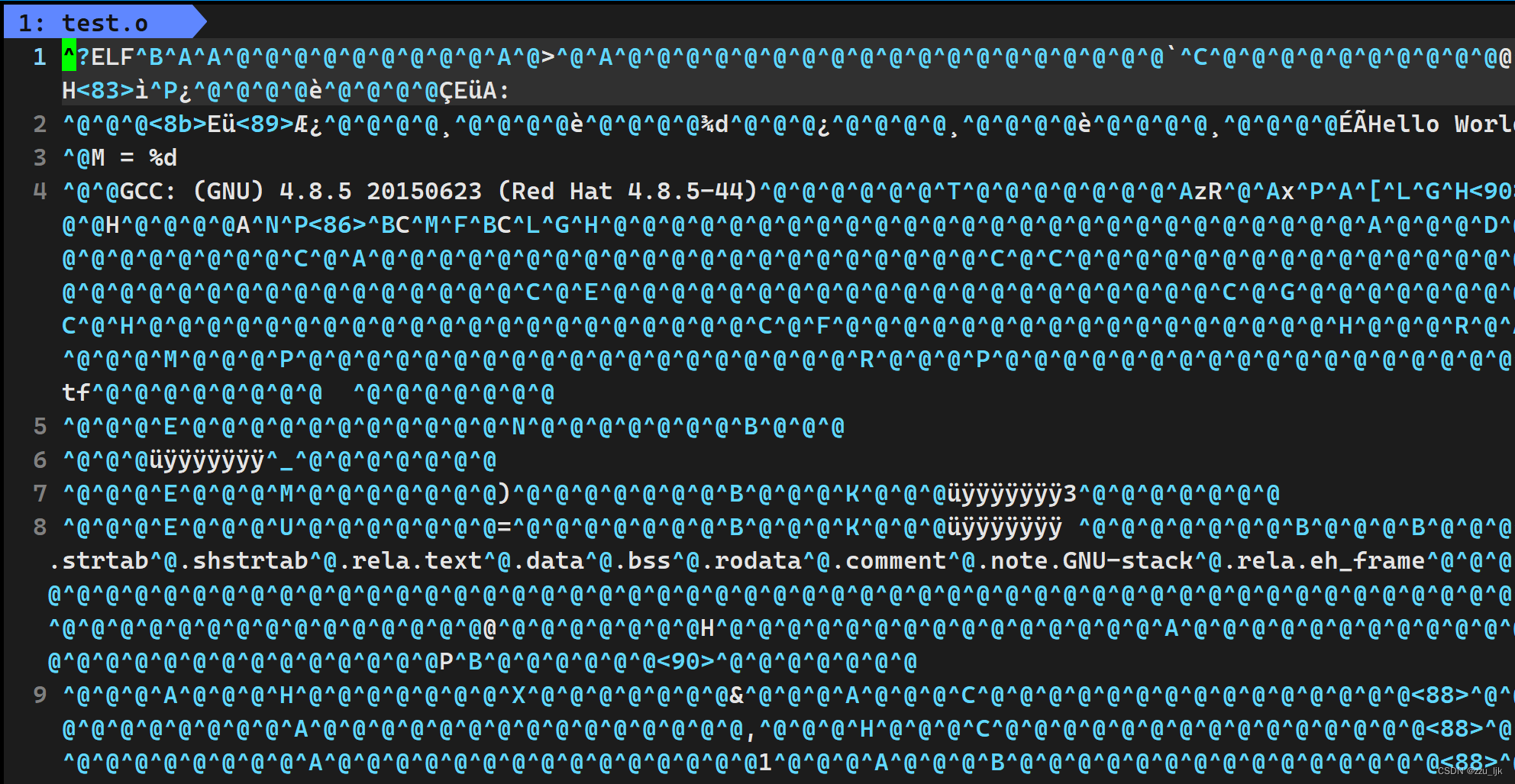
可以发现都是机器才能看懂的二进制代码,所以说,在汇编阶段,将汇编代码转换为了二进制代码。
并且如果有两个源文件,比如test.c和add.c,这个时候这两个文件会生成自己的符号表,用来保存刚才编译汇总的那些符号,在test.c中定义的函数,会将这个函数以及它对应的地址放在这个文件符号表中,但是声明则不会。声明也会将函数放入符号表中,但是会给这个函数生成一个无效的地址。
所以,汇编阶段,就是将汇编代码转换为二进制代码,同时将编译阶段汇总的符号放在符号表中,后续链接阶段会用到这个符号表。
链接
输入下面指令,进行链接

这里就不需要添加什么其他的指令了,直接编译即可。编译后得到的文件就是可执行程序了,我们运行这个程序就能得到我们想要的结果了。
链接其实有两个动作:一是段表的合并,二是符号表的合并和重定位,各是什么意思呢?
合并段表:简单说一下,我们生成的add.o文件和test.o文件都是二进制的,在LInux中,它们符合elf格式。Linux下的可执行程序也是elf格式的,我们这里就是将相同格式的文件进行合并。
符号表的合并:多个符号表合并成一个符号表,每个符号选取其有效的地址。在链接阶段能不能使用这个符号,就取决于这个符号有没有一个有效的地址。
如果某个符号没有定义或者在两个源文件中都有定义,就会发生链接错误。
在C++的函数重载中,符号表中会根据函数的参数对函数名进行修饰,不用担心函数重名的问题。
总结
在预处理阶段,将头文件展开,进行注释的删除和宏替换。
在编译阶段,将C语言代码转换为汇编代码,进行:语法分析,词法分析,符号汇总和语义分析。
在汇编阶段,将汇编代码转换为二进制代码,并且进行生成符号表。
在链接阶段,生成可执行程序,合并段表并进行符号表的合成和重定位。
其他的一些小问题:
如果想深入了解,推荐书籍《程序员的自我修养》。